
AI is changing how people find and read information online.
Tools like Google AI Overviews, Perplexity, and ChatGPT no longer just list links, they write full answers using content from across the web.
That means your articles, reports, and data may already be helping AI generate responses ,often without clear credit or visibility.
This is where Retrieval-Augmented Generation (RAG) comes in.
RAG helps AI systems read your content correctly, cite it properly, and respect your rights. It turns your website into a trusted, structured source that AI can reference safely and even pay for through licensing.
In this guide, you’ll learn what RAG means, why it matters for publishers, and how to prepare your site step by step.
By the end, you’ll know how to make your content more discoverable, citable, and profitable in the age of AI search and conversation.
What Is Retrieval-Augmented Generation (RAG) for Publishers?
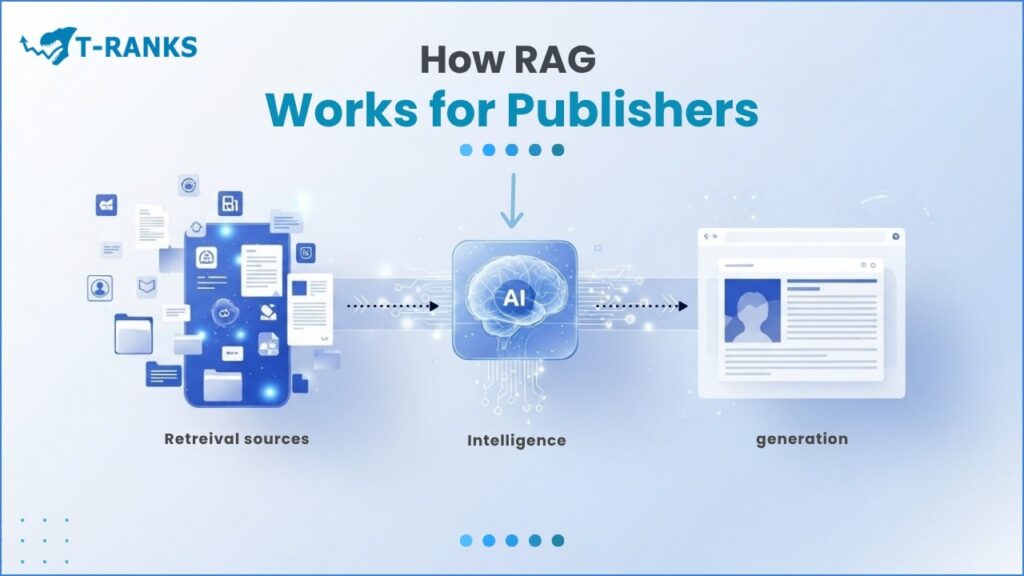
Retrieval-Augmented Generation (RAG) is a way for artificial intelligence (AI) to give more accurate and reliable answers.
It works in two steps: retrieval and generation.
First, the AI searches for real and trusted information. Then, it uses that information to write the final answer.
Think of it as teaching AI to look before it speaks. Instead of guessing, it checks real data sources like your website, articles, or reports before replying.
When someone asks a question on ChatGPT, Perplexity, or Google’s AI Overview, RAG helps those systems find facts from reliable publishers and then include them in their response. That’s why users might see answers like:
“According to [YourSite.com]…”
This is RAG in action—it helps AI produce answers based on verified content and gives proper credit to the original source.
For publishers, RAG means your content can directly feed into AI systems. It turns your website into a trusted reference that AI tools can quote and cite in their responses. Instead of being one of many sites on the internet, your content becomes part of the “live knowledge” that powers the next generation of search.
In simple words, RAG for publishers is about making your site discoverable and citable by AI. It connects your publishing archive to AI models, helping your work appear inside AI-generated summaries and answers—just like how Google shows featured snippets.
Example
Imagine you run a learning website and post an article called “How Interactive Learning Improves Memory Retention.”
Later, someone asks an AI assistant, “Does interactive learning really help students remember better?”
The AI finds your article, reads the facts, and replies:
“According to EduInsights.com, interactive learning can improve memory retention by up to 60%.”
Your article is cited as a trusted source, giving your brand more visibility and authority.
Who Are “Publishers”?
In this context, publishers include anyone who shares valuable content online, such as:
- News and magazine websites
- Academic journals and research archives
- Educational or training platforms
- Blogs and online resource libraries
- Business and industry publications
- Creators or organizations sharing guides, studies, or multimedia content
If your content can be read, shared, or cited online, you’re part of the RAG ecosystem.
How RAG Works in Practice
Retrieval-Augmented Generation (RAG) combines two main abilities of artificial intelligence: retrieving information and generating answers. It allows AI systems to use your verified content to produce accurate, cited, and trustworthy responses.
Here’s how the process works from start to finish.
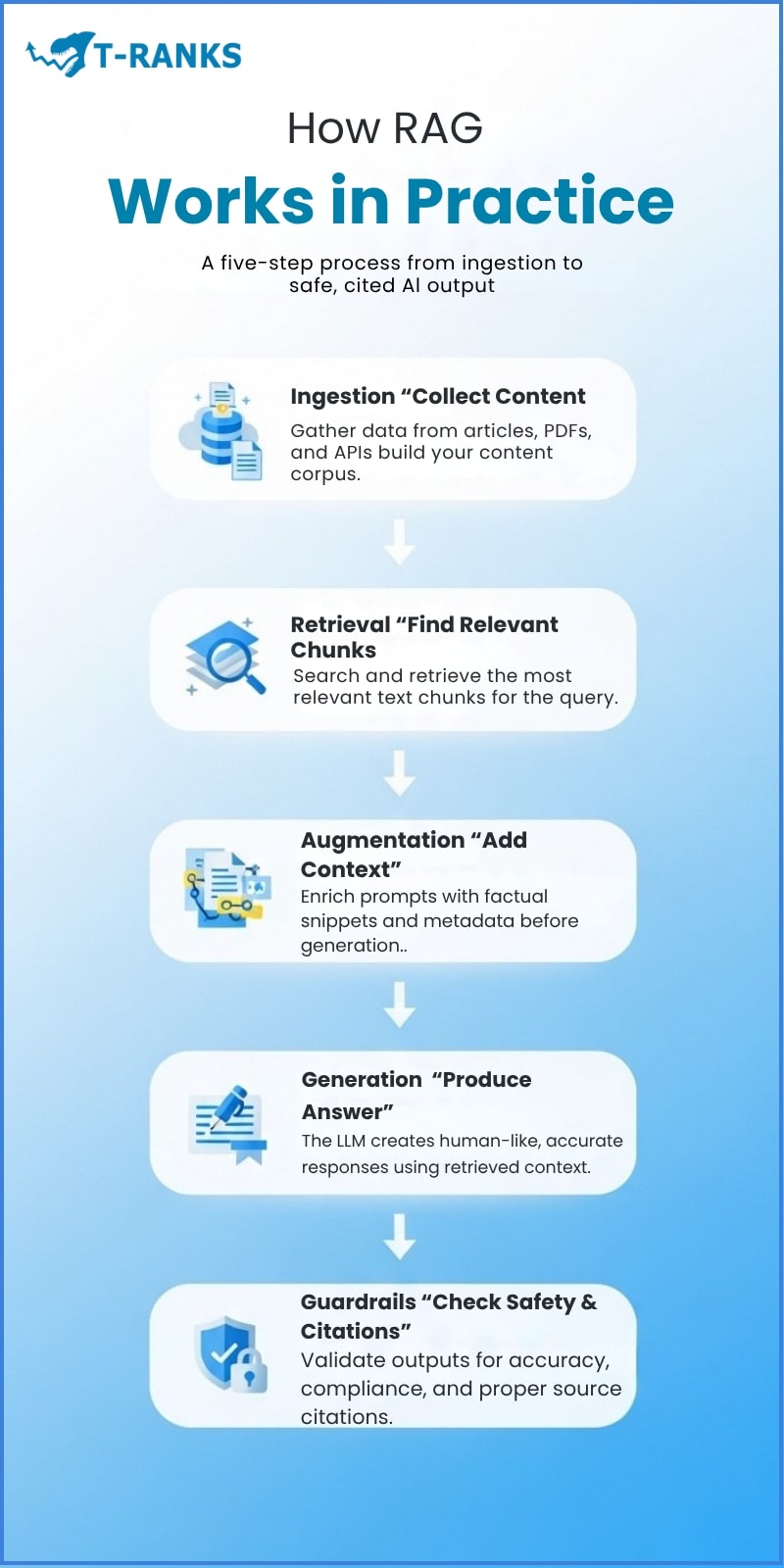
1. Ingestion – Preparing Your Content
First of all, the system collects and processes your content. It gathers articles, reports, and studies from your website or archive and converts them into a format that machines can understand. Each document is cleaned, organized, and labeled with details such as the title, author, publication date, and topic.
After this, the content is stored in what’s known as a vector database, a technology that helps AI understand the meaning of words and ideas instead of just matching keywords. This approach is similar to how Google’s Knowledge Graph connects related information through entities and context rather than simple text matching.
2. Retrieval – Finding the Right Information
Once your content is ready, the retrieval process begins. When someone asks a question, the system searches your database to find the most relevant pieces of information. Instead of looking for exact phrases, it understands the meaning behind the question and identifies related ideas or terms.
For example, if a user asks about “heart health,” the system can also find content that uses terms like “cardiovascular fitness.” It then extracts short, focused sections from your articles that answer the question directly. This ensures that only credible and topic-aligned information is used to build the AI’s response, using techniques similar to semantic similarity search explained in Ahrefs’ guide to Semantic SEO.
3. Augmentation – Adding Context for Accuracy
After retrieving the right pieces, the system combines them with the user’s question. This step creates a detailed prompt that gives the AI clear context before it starts writing.
You can think of it like giving the AI a stack of highlighted notes from your archive. It no longer has to guess; it can write confidently based on your verified facts and research. This is the same concept described in OpenAI’s Retrieval-Augmented Generation framework, where verified data guides the model’s output to ensure factual accuracy.
4. Generation – Writing the Answer with Citations
Next, the large language model uses this prepared prompt to write a complete and well-structured answer. It relies only on the verified information that was retrieved earlier, which makes the response both accurate and trustworthy.
In this stage, the system also adds citations and links that point back to your original articles, reports, or studies. Your content becomes the backbone of the AI’s knowledge, and every answer includes proper attribution to your brand.
5. Guardrails – Ensuring Quality and Compliance
Finally, before the AI’s answer is shown, the system performs several checks. It reviews the content for accuracy, bias, and licensing permissions to make sure your material is used correctly. It also verifies that the response meets editorial standards and aligns with your publication’s voice and policies.
These final checks make the process safe, transparent, and consistent with your brand’s integrity. In the end, RAG ensures that your content fuels the next generation of AI answers without losing its accuracy or ownership.
In Short: RAG turns your archive into a living library that AI can search, cite, and trust — helping publishers stay relevant and visible in the era of intelligent search.
Why RAG Matters Now: Discover, Monetize, Be Cited

The way people find and consume information has changed. AI platforms like Google AI Overviews, Perplexity, and ChatGPT now guide what millions of readers see first. For publishers, this shift means success is no longer about ranking high on Google. It’s about whether AI systems can access, understand, and cite your content.
That’s where Retrieval-Augmented Generation (RAG) becomes essential. RAG connects your articles, research, and archives to modern AI systems so they can pull accurate facts directly from your site. It helps your content stay visible, credible, and profitable in the new AI-driven web.
Discover – Be Found Where Readers Ask
RAG turns your content into something AI can actually find and use. When someone asks a question like “What’s driving inflation in 2025?”, the AI can pull insights directly from your verified reports instead of guessing or using outdated data.
Your brand becomes part of the answer itself — not a link buried in search results. RAG keeps older articles useful by refreshing their context and ensures new ones are indexed fast, so they appear in real-time AI conversations, summaries, and voice searches.
In Simple Terms: You stay discoverable wherever people are asking questions — not just searching keywords.
Be Cited – Build Trust and Authority
In this new landscape, citations are the modern measure of trust. When an AI tool says, “According to [YourSite.com]…”, it’s crediting your expertise as the source of truth. Each citation works like a digital endorsement, proving your content is reliable enough for machines to use and humans to believe.
Every mention sends readers back to your site and builds authority with search engines. Over time, this helps your brand stand out as a credible, quotable voice in your niche — whether it’s news, finance, education, or research.
The more your content is cited by AI, the more valuable and trustworthy it becomes.
Monetize – Turn Citations into Revenue
RAG doesn’t just protect your content — it helps you profit from it. Instead of letting others scrape your data, you can license it directly to AI platforms, aggregators, and research partners.
Here’s how publishers are already doing it:
- Creating paid APIs that let developers use verified data from their archives.
- Keeping paywalls intact by allowing AI to quote small claim-level snippets only.
- Using RAG analytics to see which topics drive the most citations or reader conversions.
This turns your content into both a knowledge product and a data service — a valuable asset that generates income long after publication.
Why It Matters
RAG ensures your content doesn’t disappear in the AI era. It helps your brand stay visible in AI answers, builds lasting authority through transparent citations, and opens new paths for monetization.
When your site is consistently cited by AI systems, it signals to both audiences and algorithms that your work is worth trusting — and that’s what drives traffic, partnerships, and long-term growth.
In Short: RAG makes sure your stories aren’t just read — they’re recognized, cited, and rewarded.
Publisher-Grade RAG Stack: From Crawl to Citation
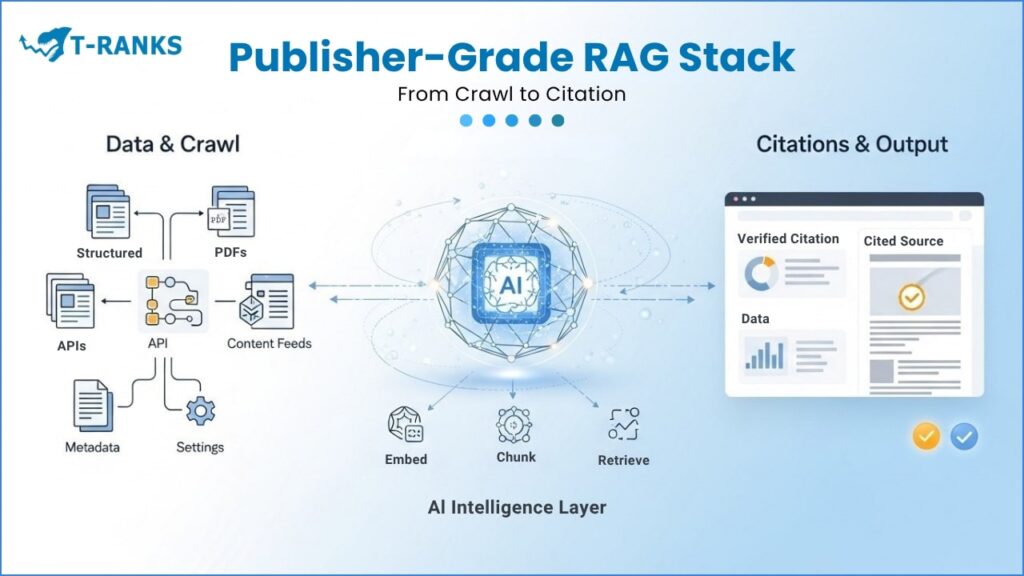
Building a publisher-grade RAG system is not about connecting random AI tools. It is about designing a smart content pipeline that helps AI see, understand, and correctly cite your work.
When done right, your site becomes more than a website. It turns into a living knowledge system that AI platforms trust. You maintain full control over structure, rights, and how your content is used.
Think of it as your editorial supply chain for the AI era. Every step, from crawling to retrieval, affects how systems like Google AI Overviews, Perplexity, and Gemini recognize your authority.
A complete RAG stack moves through these key stages: Ingestion, De-duplication, Semantic Chunking, Embeddings, Hybrid Retrieval, Re-Ranking, Generation with Citations, and Safety Checks. Together, they make sure your content is not only found but trusted, cited, and monetized.
1. Corpus Hygiene and Rights
Every strong RAG system starts with a clean, well-organized content library. Without that foundation, AI cannot retrieve or cite accurately. This stage focuses on protecting your intellectual property and preparing your data for AI discovery.
Begin with custom crawling using purpose-built APIs instead of generic scrapers. This keeps metadata such as author names, publication dates, and license information intact. Proper crawling ensures your structured data is read the same way Google Developers recommends for schema markup, improving both visibility and accuracy.
Maintain data quality and security by converting all content—HTML, PDF, or XML—into a consistent format. Apply encryption and access control to comply with privacy standards like GDPR.
Tag every file by license type—open, paid, or restricted—so that AI systems only use what is legally cleared for citation. Keep one canonical URL for each article and track all revisions to prevent AI from citing outdated versions.
Set up freshness automation through time-to-live scheduling so new or time-sensitive stories automatically refresh. Exclusive or premium reports should have embargo tags that delay AI access until they are ready for release.
The result is a structured and compliant content base that AI platforms can trust and cite with full confidence.
2. Chunking That Wins Citations
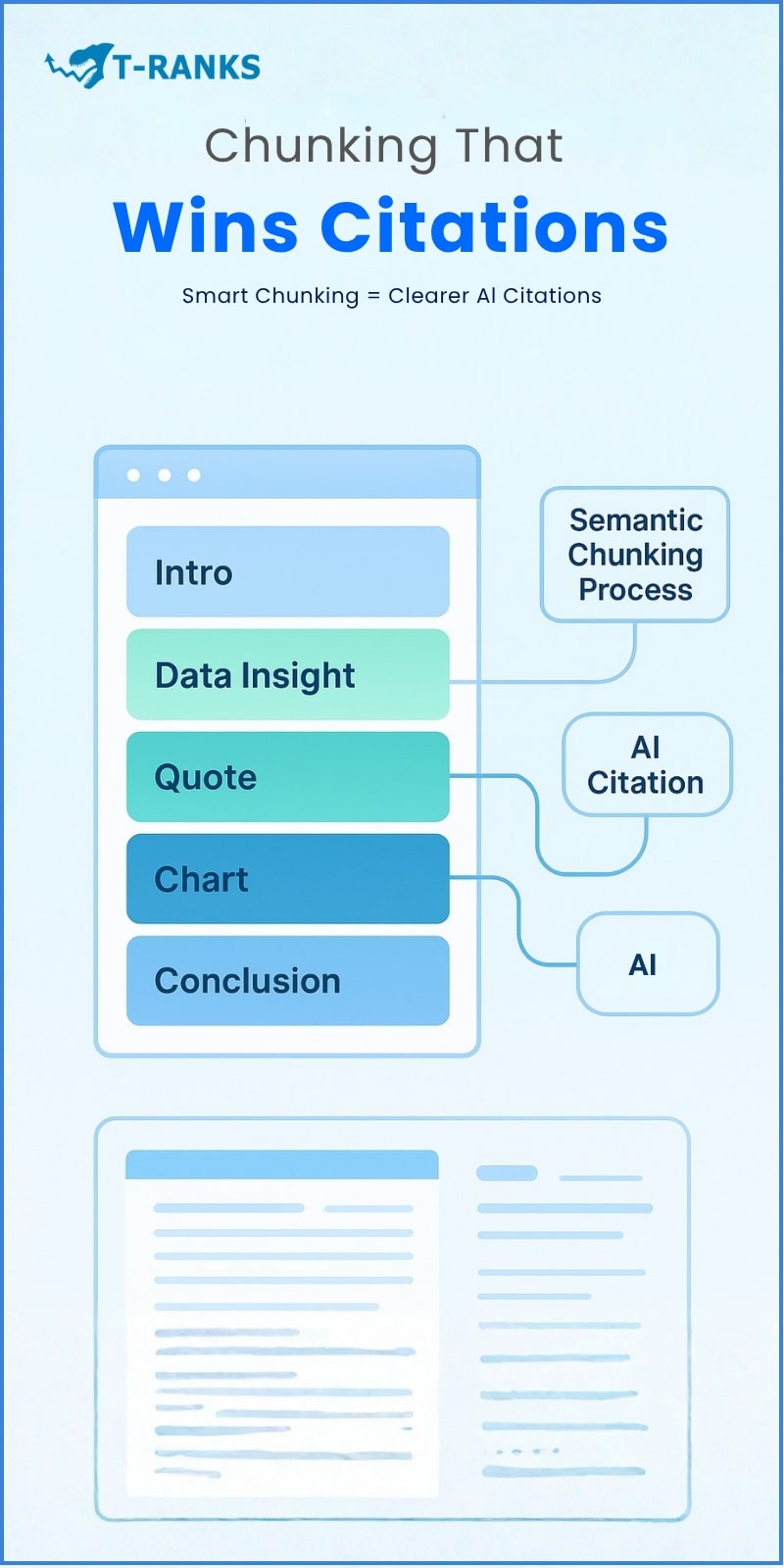
If content hygiene is the foundation, chunking is the architecture. It determines how precisely AI retrieves and attributes your work.
Divide your articles into smaller, meaningful sections such as introductions, summaries, and key findings. This structured approach mirrors how Ahrefs describes semantic SEO — helping machines understand meaning and relationships rather than just keywords.
Each chunk should include metadata like title, author, and source URL. This allows AI to create inline citations automatically when referencing your work.
Create both small and large chunks. A single statistic can be one chunk, while its surrounding paragraph adds valuable context. Include visuals such as tables and charts by converting captions into text, since modern AI models treat these as retrievable data points.
Label every chunk with a descriptive title, such as “Chart: Energy Demand 2025” or “Insight: Subscription Growth in Finance Blogs.” Semantic labels improve retrieval accuracy and citation frequency.
When chunking is done well, AI retrieves the right information, cites it clearly, and attributes it back to your brand . This is just like we explain in Forum Backlinks Strategy where precise context improves trust and authority.
3. Retrieval That Surfaces Your Best Work
Retrieval decides which of your articles appear when AI generates an answer. Strong retrieval ensures your most credible and recent content is the one that gets cited.
Combine keyword-based search with vector-based retrieval, which understands meaning and intent rather than exact phrases. This hybrid method, similar to OpenAI’s Retrieval-Augmented Generation framework, helps AI pull both factual and contextually related insights from your archive.
Prioritize your own domain so your canonical version always outranks syndicated or duplicated material. Re-rank articles based on quality factors such as author expertise, recency, and engagement.
For complex topics, your RAG system can run multi-step retrievals, gather multiple perspectives, and synthesize a complete answer within your ecosystem.
Enable inline citations so every AI-generated answer links back to your pages, driving referral traffic and reinforcing trust. Give updated stories a visibility boost, as AI engines prefer current, timestamped content.
Final Takeaway: A publisher-grade RAG stack is more than a technical system — it is your long-term strategy for staying visible and credited in the AI era. It helps your content remain accessible, protected, and profitable while ensuring every AI-generated answer points back to you.
By perfecting corpus hygiene, chunking, and retrieval, publishers build a future-proof knowledge base that turns every verified article into a trusted data source.
Ready to future-proof your content? Architect your RAG Stack with T-RANKS and transform your publishing archive into a scalable, AI-ready citation engine that generates trust, traffic, and revenue.
Content Patterns That LLMs Prefer (Publisher Edition)

Modern AI systems like Perplexity, Gemini, and ChatGPT don’t just read your content—they analyze and rank it. They prefer articles written with clarity, structure, and factual grounding. When publishers follow these content patterns, their work becomes AI-visible, citable, and monetizable.
At T-Ranks, we help publishers design content architectures that large language models actually understand—from schema markup to citation-friendly structures. These methods make your publication stand out in AI search results while preserving your editorial integrity.
Key formats LLMs reward:
- Answer-first summaries: Start with a short, direct takeaway.
- Bulletproof facts: Include verified data or credible stats.
- Stat boxes and callouts: Highlight key numbers or definitions.
- Per-article FAQs: Address reader or AI-driven questions.
- Verdict paragraphs: End sections with clear conclusions.
- Schema markup: Use JSON-LD (Article, NewsArticle, FAQPage) for structure and timestamps.
Together, these make your content a trusted data source—ready for inclusion in AI-generated answers and summaries.
“Answer Card” Intros
An Answer Card Intro is a concise, AI-friendly opening that summarizes your topic before readers scroll or AIs parse the text. It’s the first signal that tells models your article has authority and clarity.
How to create one:
- Keep it between 60–80 words with natural keywords and the main answer upfront.
- Add two to three short data bullets—numbers, dates, or stats—to back your summary.
- Apply Article schema so AI systems know it’s the official answer block.
Example:
RAG-optimized news platforms gained 35% more AI citations in 2025, as publishers structured content for factual retrieval.
- 35% citation growth among top 100 outlets (T-Ranks Data, May 2025).
- 18% increase in referral traffic from AI Overviews (#citations-2025).
- T-Ranks clients saw 1.4× higher visibility in Perplexity results (#rank-2025).
T-Ranks Insight:
We benchmark “Answer Card Intros” to measure which wording patterns trigger higher AI citation rates—then optimize your newsroom templates for that style.
Evidence Blocks & Tables
LLMs rely on structured data they can parse and verify. Evidence blocks and tables make your facts machine-readable, reducing hallucinations and improving citation consistency.
How to use them:
- Create tables with columns like Metric, Method, Sample, Date, Source.
- Include anchor links or IDs so AI can trace citations precisely.
- Use Dataset or Observation schema for machine clarity.
Example:
| Metric | Method | Sample | Date | Source |
| AI Citation Accuracy | Cross-Platform Audit | 120 Publishers | 2025-06 | T-Ranks Benchmark |
T-Ranks Insight:
Our RAG Evaluation Dashboard tracks how structured evidence improves retrieval accuracy and citation frequency across major AI models.
Make Paywalls RAG-Friendly (Without Giving It All Away)
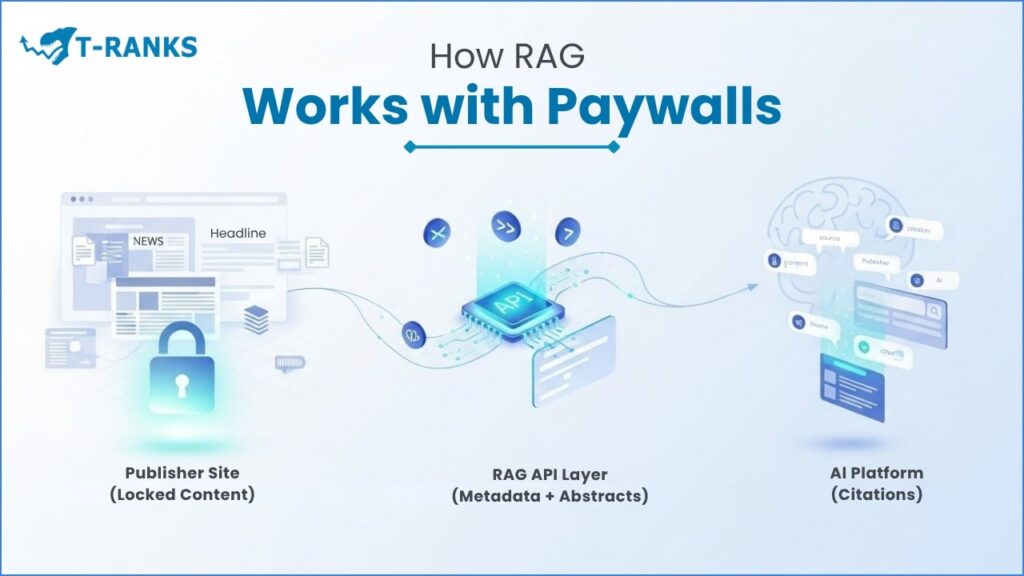
A RAG-friendly paywall helps publishers stay visible without losing control of paid content. It allows AI tools like Gemini, Perplexity, and ChatGPT to find and credit your work while keeping your full articles protected.
This approach makes your paywall smarter, not weaker. It mixes simple access rules with structured design so you can protect your content, get proper credit, and earn from new sources such as content APIs, AI licenses, and partner programs.
Teaser Abstracts: Share Context, Protect Value
A teaser abstract gives AI and readers a short summary of your article. It helps them understand what your story is about without showing the full details. These short pieces (about 100–150 words) act like a public preview that improves visibility and encourages subscriptions.
Example: “Renewable energy capacity expanded 14% last year, led by new wind projects in Asia and Europe. The full report explores cost shifts, policy incentives, and investor trends shaping 2025’s clean-energy landscape.”
Add Article or NewsArticle schema and timestamps to make these abstracts machine-readable. This ensures AI crawlers can identify your content as original and trustworthy, following Google Developers’ schema guidelines.
Claim-Level Snippets: Let AI Cite You, Not Copy You
Claim-level snippets are short facts or verified statements placed outside your paywall. Each snippet includes a date, a source, and a claim ID. This allows AI systems to use your data and still give you credit.
Example: “Electric-vehicle adoption increased year-over-year in 2025 (Source: International Energy Agency, May 2025).”
This method helps your site become a trusted source of verified facts. It gives AI the information it needs without exposing your premium analysis. It also boosts credibility, similar to the semantic structure explained in Ahrefs’ guide to Semantic SEO.
Licensable Citations Endpoint: Turn Visibility into Revenue
A citations endpoint is a simple API that lets approved AI systems access your metadata or summaries. You decide what they can see, and each request is logged and tracked.
For example, you can create a “Content Access API” that allows free access for previews and paid access for full retrieval. This way, your data stays protected, and every AI interaction can generate income.
T-RANKS helps publishers build these secure systems so your content is visible, properly credited, and safely monetized.
Metered Access for Bots: Reward the Verified, Restrict the Rest
Instead of blocking every crawler, you can allow limited bot access to trusted AI systems. For instance, verified bots can view the first 200 words of an article once per day.
This balance keeps your content protected while still visible to AI tools. It allows your brand to appear in AI answers without losing control of your paywall.
Authenticated Feeds for Partners: Private Access, Public Trust
For research platforms or enterprise clients, create authenticated feeds through secure APIs or RSS streams. These feeds can include structured metadata, abstracts, or verified claims under paid licensing agreements.
For example, a research partner could license access to your archives so its AI assistant pulls verified insights directly from your database. Every request is logged, tracked, and credited to you.
Compliance and Protection
Once your paywall is ready for AI, monitor how bots and partners use it. Run AI-access audits to confirm that only verified systems can view your structured content. Check that every citation follows your content and licensing policy.
This ongoing monitoring protects your brand, builds trust, and ensures your content is used responsibly.
Next Step
A RAG-ready paywall helps you protect your content, earn credit, and take part in the growing AI economy. It keeps your work private for readers but still visible and citable for AI systems.
Partner with T-RANKS to build a paywall that is secure, AI-optimized, and built for long-term growth.
Revenue Models: From Pageviews to AI Licensing
Clicks don’t pay what they used to. As AI search tools like Perplexity, Gemini, and ChatGPT change how people find information, traditional ad revenue is no longer enough.
Your content is now part of a global AI knowledge network —a system that learns, retrieves, and cites verified information. This shift gives publishers a new opportunity: to license and monetize their archives as structured data.
Publishers who make their content RAG-ready, API-accessible, and rights-controlled can earn each time AI platforms use or cite their material.
AI Content Licensing
AI companies pay for verified, structured content that improves their models. This creates a new way for publishers to profit from their archives.
You can license access to your articles or data for AI training and retrieval under clear usage terms. Major media groups like News Corp and Axel Springer have already signed deals with leading AI labs to earn from archive access.
Smaller publishers can also join through emerging frameworks like IAB Tech Lab’s Content Ingest API or Really Simple Licensing (RSL), which make payments and attribution traceable.
Pay-Per-Crawl and Micro Licensing
Not every publisher can sign global deals — but anyone can earn through pay-per-crawl models. With this setup, AI bots pay for each approved crawl or data request.
Using platforms such as Cloudflare or Fastly, you can approve verified bots and deny unauthorized ones. Each valid request becomes a small, automated payment. It’s a fair system that turns AI crawling into revenue instead of data loss.
T-RANKS Tip: Pair your setup with RSL metadata to make payment and attribution transparent to AI systems.
AI-Powered Products and Services
Why only license your data when you can build your own AI tools? By using Retrieval-Augmented Generation (RAG), publishers can turn old content into useful products for subscribers or partners.
You can build simple tools such as:
- Smart subscription search that lets users ask natural questions and get verified answers.
- Data APIs that sell structured insights to researchers or businesses.
- Internal dashboards that help your editors find content gaps or trends.
These services turn your content into something interactive and valuable. You aren’t just selling access — you’re selling intelligence.
T-RANKS has helped publishers create similar tools, boosting engagement and subscription renewals.
Editorial Workflow for RAG Success
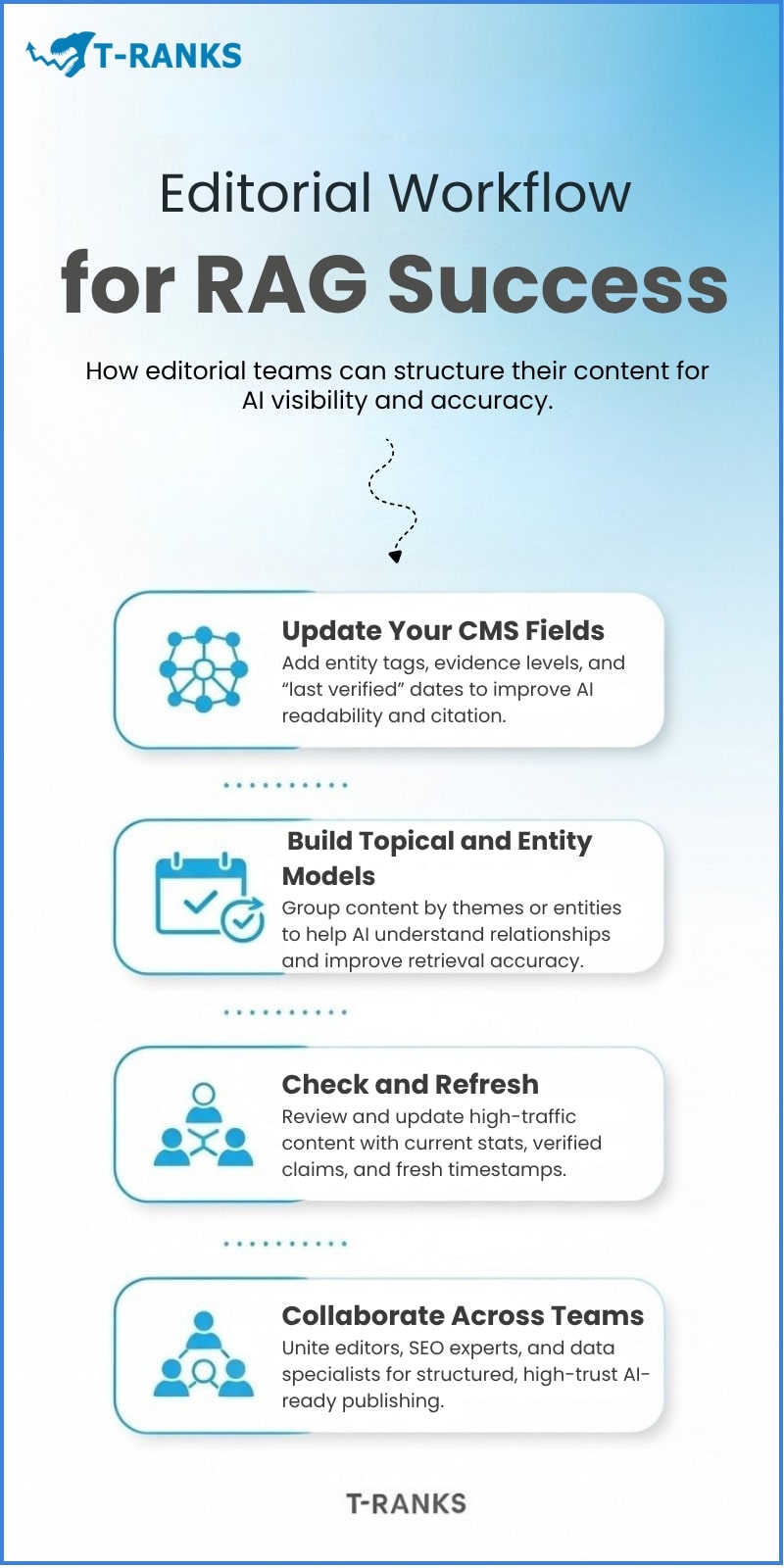
A successful RAG system doesn’t depend only on technology. It also depends on how your editorial team works. Your editors, writers, and content managers must learn to publish with AI visibility and structured accuracy in mind.
When your workflows are RAG-ready, every story you publish becomes easier for AI systems to understand, cite, and trust.
Update Your CMS Fields
Start by improving your content management system. Add fields that help structure your data, such as entity tags, evidence level, and last verified date. These details allow AI retrieval systems to identify people, organizations, and topics accurately.
Make sure each article includes a permanent source link (DOI or canonical URL) and clear authorship. This not only supports attribution but also builds your brand’s authority in AI ecosystems. If you’re unsure how to organize metadata, check Google Developers’ structured data guide for best practices.
Build Topical and Entity Models
Group your content into clusters based on topics, entities, or recurring themes. For example, a health publisher could group all articles about “mental wellness,” while a business site might cluster content under “AI in Finance.”
This structure helps AI understand your content’s relationships, improving retrieval accuracy. It also supports semantic interlinking, a concept covered in Ahrefs’ Semantic SEO guide, where related pages boost each other’s visibility through shared meaning.
Fact-Check and Refresh Regularly
RAG systems value freshness and factual accuracy. Set a regular review cycle for your most-visited or citation-worthy articles. Update statistics, replace broken links, and refresh outdated claims.
Add a “Last Verified” tag to every update so AI models and readers both know your content is current. Consistent refreshing also improves your ranking in AI summaries and answer cards.
Collaborate Across Teams
Encourage collaboration between editors, data teams, and SEO specialists. Editorial staff maintain quality and tone. SEO teams ensure structure and schema. Data specialists manage tagging, metadata, and technical accuracy.
This teamwork creates a steady flow of content that is both human-readable and AI-friendly.
T-RANKS Tip: We help publishers build RAG-ready editorial systems that merge quality writing with structured design, ensuring every update contributes to both rankings and citations.
Measuring RAG Performance: From Citations to Compliance
RAG success isn’t just about publishing structured content. It’s about measuring how your work performs across AI ecosystems. New metrics now replace traditional traffic numbers. Instead of clicks, you track how often your content is cited, retrieved, or licensed by AI systems.
Track Citations and Mentions
Start by monitoring how often AI models reference your site. You can do this by checking referrers, analyzing logs, or using AI citation trackers that identify mentions across search summaries and chat responses.
A “Citedness Score” helps measure how visible your brand is in AI results. This score combines your total number of AI citations, the quality of domains that reference you, and the sentiment around those mentions. If your citations are increasing, it means your RAG system is working effectively.
For deeper insights, platforms like OpenAI’s documentation on retrieval can help you understand how retrieval-based models identify and use credible sources.
Measure Engagement and Conversion
AI visibility should also lead to measurable results. Track metrics like Assisted Subscriptions, where new users subscribe after discovering your content through AI-powered search. Also measure API usage, showing how often your licensed data is accessed by AI systems.
You can view these metrics inside analytics dashboards or API reports. Together, they reveal the real ROI of your RAG implementation.
Monitor Compliance and Rights Usage
Visibility means little without control. Regularly audit your content usage to confirm that every AI system accessing your data is approved and compliant. Check that citations link back to your pages and that all licensed usage follows your agreed terms.
You can assign a compliance manager or automate this process through your RAG endpoint logs. It protects your rights and ensures fair compensation for every interaction.
T-RANKS Insight: We help publishers build RAG dashboards that track citations, licensing, and compliance in one place — making it easier to manage visibility and rights together.
In Summary
Modern publishing success isn’t just about pageviews or impressions. It’s about being cited, trusted, and licensed in the AI world. When your editorial workflow supports structure and your metrics focus on citations and compliance, your brand becomes part of the information backbone that powers intelligent systems.
Partner with T-RANKS: Design a RAG workflow that keeps your newsroom efficient, compliant, and profitable in the age of AI-powered discovery.
Compliance and Safety for Publishers

As publishers connect their content to AI systems, protecting rights and maintaining compliance is essential. Retrieval-Augmented Generation (RAG) opens new doors for visibility, but it also introduces risks around data use, attribution, and privacy. A safe RAG framework ensures that every citation, dataset, and partnership respects your policies and legal boundaries.
Understand Data Ownership
Before sharing data with any AI platform, confirm who owns what. Publishers should define ownership for text, images, charts, and even embedded media. Include clear licensing terms that specify how each item can be used, quoted, or monetized.
Add copyright tags, license labels, and author credits to your structured metadata. These small details guide AI models on how to reference your material safely.
If you’re unsure about legal formats, see the Creative Commons licensing guide for examples of flexible, attribution-friendly frameworks.
Control Access with APIs and Permissions
Instead of giving AI crawlers full access, use secure APIs and token-based permissions. This lets you decide who can view, cite, or reuse your content — and under what terms.
Approved AI systems can receive structured data (like abstracts or claim-level snippets) while your full articles remain private. Unauthorized bots or scrapers can be blocked automatically through verified access keys.
T-RANKS builds secure RAG endpoints that track every request and ensure only compliant systems retrieve your content.
Respect User Privacy and Data Laws
If your site collects personal data or analytics, your RAG setup must also follow privacy laws such as GDPR and CCPA. Anonymize user data before including it in any AI-readable dataset. Remove IP addresses, emails, or session IDs from archives before indexing them for retrieval.
This protects users and keeps your organization clear of legal violations. For reference, review the GDPR official overview for data-handling standards that apply globally.
Set Editorial and Ethical Boundaries
AI citations reflect your brand. Establish clear editorial policies on what data you allow AI systems to use. Mark sensitive, speculative, or embargoed content as off-limits until officially released.
Encourage editors to tag verified sources, disclose conflicts of interest, and use neutral language in fact-based reporting. This reduces the risk of bias or misinformation being amplified through AI-generated answers.
Run Safety and Quality Audits
Compliance is not a one-time task. Regular audits help you verify that all integrations, APIs, and crawlers remain within your rules. Use automated scripts or third-party tools to track unauthorized citations or license breaches.
T-RANKS helps publishers set up RAG audit dashboards that show who’s accessing your data, where citations appear, and whether every interaction follows your policy. These checks ensure that your AI visibility remains safe, transparent, and aligned with your brand integrity.
In Summary
Compliance is what keeps innovation safe. A RAG system built on legal clarity, permissions, and ethical standards protects both your business and your audience. It ensures your content can power AI discovery without risking privacy, trust, or rights.
Partner with T-RANKS: Develop a compliant, rights-aware RAG infrastructure that balances openness with protection — helping your brand stay trusted in the AI era.
Your 90-Day RAG Roadmap
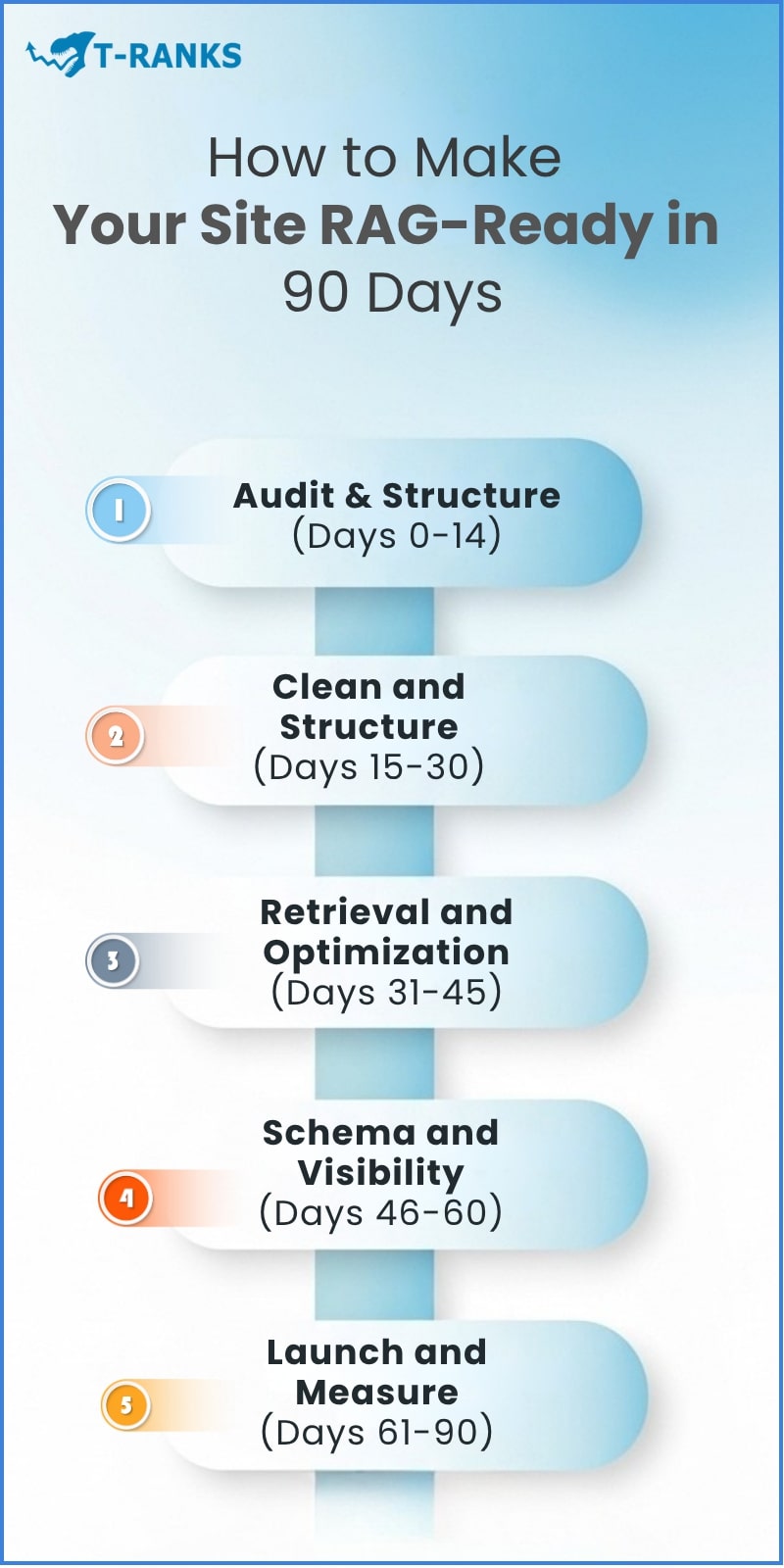
Transforming your site into a RAG-ready platform takes focus, not years. Here’s a simple 90-day plan to go from concept to measurable ROI.
Step 1 (Days 0–14): Audit and Strategy
Review your archives, metadata, and licensing. Identify your most valuable topics — the ones AI is likely to cite. Set clear KPIs like citation growth, retrieval accuracy, and subscription conversions.
Step 2 (Days 15–30): Clean and Structure
Clean URLs, add metadata, and tag every article. Break long content into smaller sections (semantic chunks) so AI can cite the right part of your article every time.
Step 3 (Days 31–45): Retrieval and Optimization
Connect your database with hybrid retrieval tools like Pinecone or Qdrant. Use ranking signals like freshness and editorial quality to surface your best work first.
Step 4 (Days 46–60): Schema and Visibility
Add structured schema markup like Article or NewsArticle. Create short summaries (Answer Cards) that AI tools can cite easily. Include FAQs and clear conclusions to guide AI answers.
Step 5 (Days 61–90): Launch and Measure
Open your API for verified AI partners. Track metrics like citations, API usage, and new subscribers. Every citation becomes a measurable asset that builds both revenue and authority.
Conclusion
In conclusion, Retrieval Augmented Generation (RAG) empowers publishers to regain visibility, trust, and revenue in the AI-driven landscape. By structuring content for retrieval, adding schema markup, and offering licensed access, your archives evolve into living data assets that are discoverable, citable, and profitable. RAG bridges technology with credibility, ensuring your expertise powers AI systems instead of being overlooked.
To stay ahead in this new era, partner with T Ranks to design and implement your RAG Ready Publishing Stack that transforms every article into a measurable and monetizable AI citation.
Frequently Asked Questions (FAQs)
Can we make RAG work with a hard paywall?
Yes, RAG can work with a hard paywall by exposing claim-level snippets and structured metadata while keeping full articles locked. Offer authenticated retrieval to licensed AI partners so your content remains citable without leaking subscription value.
Will RAG reduce our pageviews?
No, RAG typically shifts value rather than reducing it. Instead of raw traffic, you gain visibility through AI citations, subscription conversions, and licensing revenue. Publishers using teaser summaries and “read more” funnels often maintain or even increase total engagement.
How much content do we need for a meaningful RAG corpus?
You can start seeing results with around 1,000 well-tagged, high-quality articles. A smaller, structured dataset with clean internal linking and fresh updates often outperforms massive archives with poor metadata or inconsistent chunking.
Do PDFs hurt RAG performance?
No, not if processed correctly. Convert PDFs to structured HTML, preserve headings, figures, and captions, and attach section-level metadata for retrieval. Clean parsing ensures your research or reports remain discoverable and accurately cited by AI systems.
How do we prevent LLMs from misquoting us?
Use unambiguous claim blocks, citeable IDs, and canonical anchors for key statements. Maintain logs of crawler access, watermark snippets, and monitor for unlicensed citations to ensure your content is represented accurately across AI platforms.
What’s the fastest way to get cited next month?
Publish Answer-Card intros and add FAQ schema to your top 50 evergreen articles. Refresh timestamps, use descriptive metadata, and expose a lightweight citations endpoint to make your content instantly referenceable by AI models.
Does RAG require expensive infrastructure to start?
No, many publishers launch effective pilots using affordable vector databases and open-source retrieval frameworks. You can scale gradually by starting with a limited content set and expanding as ROI from licensing and AI citations grows.