
Google does not crawl every page on your website all the time. It has limited resources, and how those resources are used can affect how quickly your pages are discovered and updated in search results.
Bad backlinks can quietly waste that crawl time. When low-quality links send Googlebot to broken, thin, or unnecessary pages, the crawler still visits them. While this is happening, important pages on your site may be crawled less often or discovered later.
Backlinks play a key role in how Googlebot finds URLs. If external links point to weak or outdated pages, Googlebot follows those paths first. That early crawling uses real resources, even if the pages never appear in search results.
This article explains what crawl budget means, how backlinks influence crawling behavior, how bad backlinks drain Googlebot resources, and why crawl problems often appear long before rankings visibly change.
What Crawl Budget Really Means in Google Search
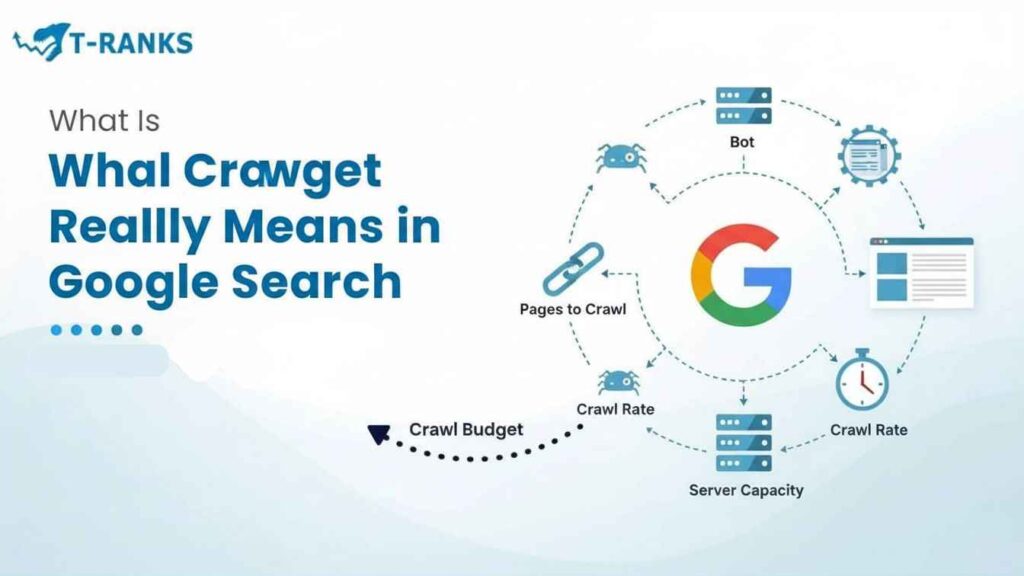
Crawl budget is the amount of time and effort Googlebot is willing to spend crawling pages on a website. It determines how many pages Googlebot visits and how often it comes back to check them.
Google uses Googlebot to discover and read web pages. Because the web is extremely large, Googlebot cannot crawl every page on every site all the time. To manage this, Google limits how much of each website it crawls. This limit is known as crawl budget.
In simple terms, crawl budget reflects how Googlebot allocates its limited resources. If a website has many pages, Googlebot may not crawl all of them. Instead, it focuses on pages that appear useful, important, and easy to reach.
A simple example helps explain this. Imagine a librarian with thousands of books but only a few hours in a day. The librarian checks the most important and frequently used books first. In the same way, Google manages billions of web pages and can only crawl a limited number of pages from each website. That limit is the site’s crawl budget.
Why Googlebot Cannot Crawl Everything Endlessly
Googlebot cannot crawl everything endlessly because the web is constantly growing. New pages, updates, and URL variations are created every second across millions of websites.
At the same time, Googlebot must divide its attention among all websites. Some sites are updated often and return useful content, while others change rarely or contain low-value pages. To stay efficient, Googlebot prioritizes crawling sites and pages that appear more valuable and reliable, while limiting crawl activity on weaker or less useful areas.
Crawling vs Indexing and Why the Difference Matters
Crawling and indexing are two different steps in how Google processes web pages. Crawling is the discovery stage, where Googlebot finds and fetches pages. Indexing is the evaluation stage, where Google decides which pages should appear in search results.
When crawl budget is wasted, indexing slows down. If Googlebot spends time crawling low-value pages, duplicate URLs, or broken links, it reaches important pages later. This delays the indexing of new content and updates, which can reduce search visibility even when content quality is good.
Why Googlebot Efficiency Matters in Modern Search

Googlebot efficiency matters because modern search depends on speed and prioritization, not unlimited crawling. As the amount of web content grows faster than Google can process, Googlebot must carefully decide where to spend its limited crawl resources.
In 2026, the web is filled with auto-generated pages, programmatic URLs, and low-quality content. This has turned crawl efficiency into a competitive factor. Websites that are easy for Googlebot to crawl and understand are revisited more often, while inefficient sites fall behind even when their content quality is similar.
To understand why efficiency has become so important, it helps to look at the main pressures Googlebot faces today.
Explosion of Auto-Generated Content
Auto-generated content has greatly increased the number of low-value pages competing for crawl attention. AI tools, templates, and content feeds can create thousands of URLs with little unique value.
When Googlebot spends time crawling these repetitive or shallow pages, fewer resources remain for important content. As a result, sites with large amounts of low-value pages often lose crawl priority first.
Spam, Programmatic Pages, and Low-Quality URLs
Spam and programmatic URLs create unnecessary crawl activity that competes with real content. These include thin archives, filter combinations, internal search pages, and URLs introduced through spam backlinks.
Even if these pages never rank, Googlebot may still crawl them during discovery. Each unnecessary crawl reduces how often important pages are revisited, slowing indexing and content updates across the site.
Why Google Increasingly Optimizes for Efficiency
Google focuses on crawl efficiency to protect search quality and system resources. Crawling billions of unnecessary URLs wastes computing power and reduces how quickly valuable content can be refreshed.
Modern Googlebot systems favor websites that return useful content and allow clean crawling paths. Over time, efficient sites receive more consistent crawl attention, while inefficient sites are quietly deprioritized without penalties or warnings.
Common Crawl Budget Problems Not Caused by Backlinks

Not all crawl budget problems come from backlinks. In many cases, crawl budget is wasted because of internal site issues that create unnecessary or duplicate URLs. These problems cause Googlebot to spend time crawling pages that do not add real search value.
Understanding these common issues helps explain why crawl inefficiency can exist even on sites with clean backlink profiles. It also helps separate internal crawl problems from backlink-related crawl waste, which is discussed later.
Duplicate URLs
Duplicate URLs waste crawl budget by forcing Googlebot to crawl the same content multiple times under different addresses. Even when pages look identical to users, Googlebot must crawl each version to understand how they relate.
Common causes include missing canonical signals, HTTP and HTTPS versions, trailing slash variations, and multiple category paths. Each duplicate version consumes crawl resources without improving indexing or visibility.
URL Parameters and Filters
URL parameters and filters create many URL variations that appear unique to Googlebot. These are often added for tracking, sorting, or filtering content.
Session IDs, tracking codes, and sort options can generate dozens or even hundreds of crawlable URLs for the same page. Googlebot may attempt to crawl these variations even when the content is nearly identical, increasing crawl demand without adding value.
Faceted Navigation
Faceted navigation multiplies crawlable URLs from a limited set of pages. This issue is common on ecommerce and large catalog websites.
Filters such as size, color, price, or availability can create thousands of URL combinations. Googlebot may explore many of these paths, reducing the crawl attention available for core category and product pages.
Thin and Low-Value Pages
Thin and low-value pages consume crawl budget without providing meaningful indexing value. These pages often exist by default rather than by design.
Examples include empty tag pages, shallow category pages, internal search results, and placeholder URLs. Even when they never rank, Googlebot may still crawl them during discovery if they are linked internally.
How Backlinks Influence Crawl Discovery and Exploration
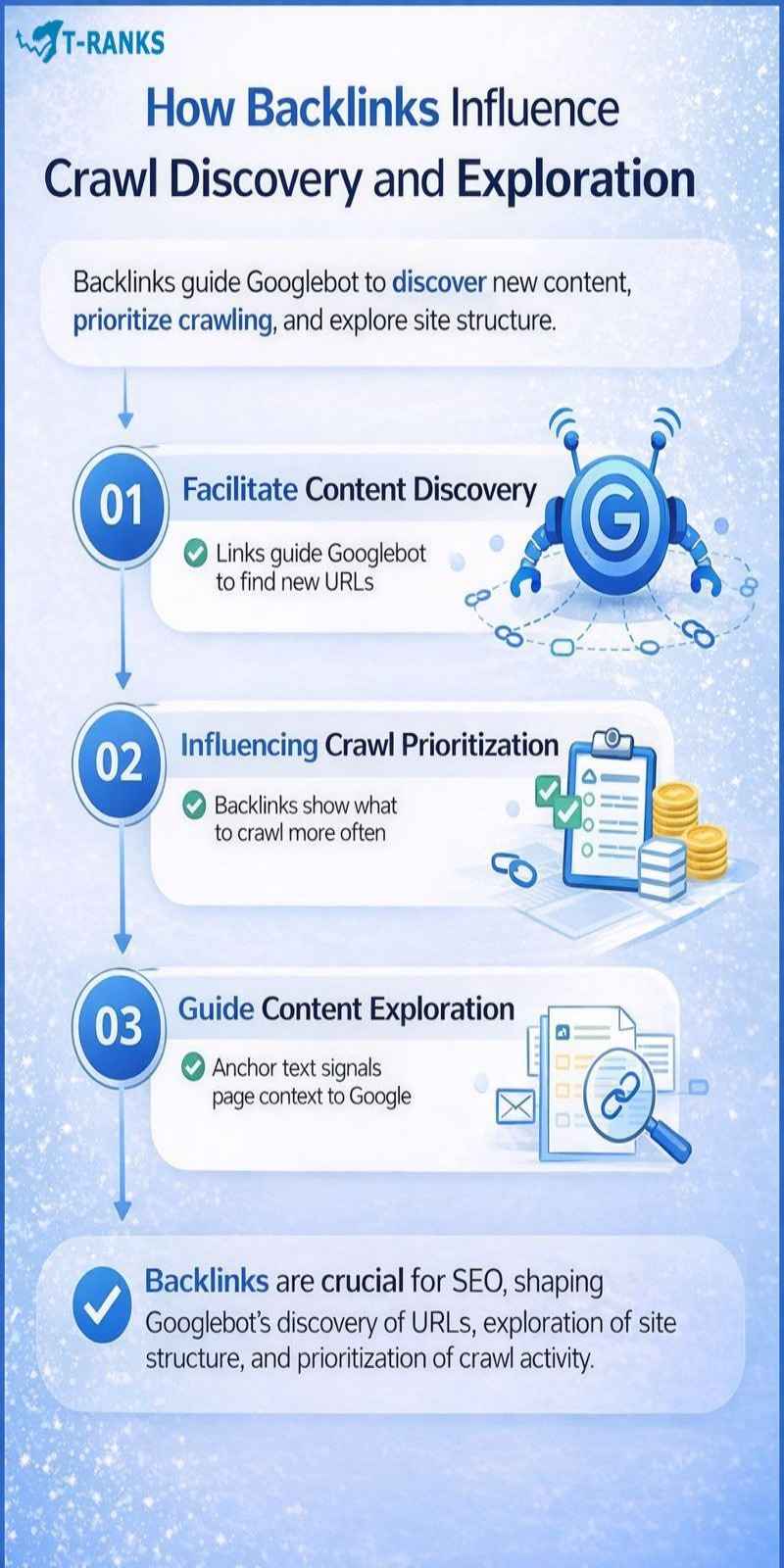
Backlinks influence crawl discovery and exploration by acting as signals that guide Googlebot across the web. Before Google decides how a page should rank, it must first discover and crawl that page. Backlinks play a major role in this early stage.
To understand this, it helps to look at how Googlebot uses backlinks during crawling.
Backlinks Help Googlebot Discover URLs
Googlebot discovers new pages by following links from one page to another. When an external website links to a page, it creates a direct path that Googlebot can follow.
Backlinks are especially important for pages that are not strongly connected through internal links. A page with no backlinks can become orphaned, meaning Googlebot may rarely find or revisit it. When backlinks exist, Googlebot is more likely to discover the URL and crawl it sooner.
Backlinks Influence Crawl Priority and Frequency
Backlinks also affect how often Googlebot crawls a page. When a page receives links from other websites, it signals that the URL may be active or worth revisiting.
This does not only affect rankings. It increases crawl demand. Pages that receive backlinks may be crawled more frequently, while pages without links may be crawled less often. This directly affects how crawl budget is distributed across a site.
Backlinks Shape How Googlebot Explores a Website
Google uses the context around backlinks, such as anchor text and surrounding content, to understand what a page is about. This helps Googlebot categorize pages during crawling and decide which sections of a website are more important.
Along with internal links, backlinks influence how Googlebot explores site structure. Sections that receive more external links may attract more crawl attention, while other areas receive less.
In Summary
In summary, backlinks do more than support rankings. They influence how Googlebot discovers URLs, decides where to crawl, and allocates crawl attention before any ranking evaluation happens. This is why backlinks can affect crawl budget long before changes appear in search results.
How Bad Backlinks Waste Crawl Budget
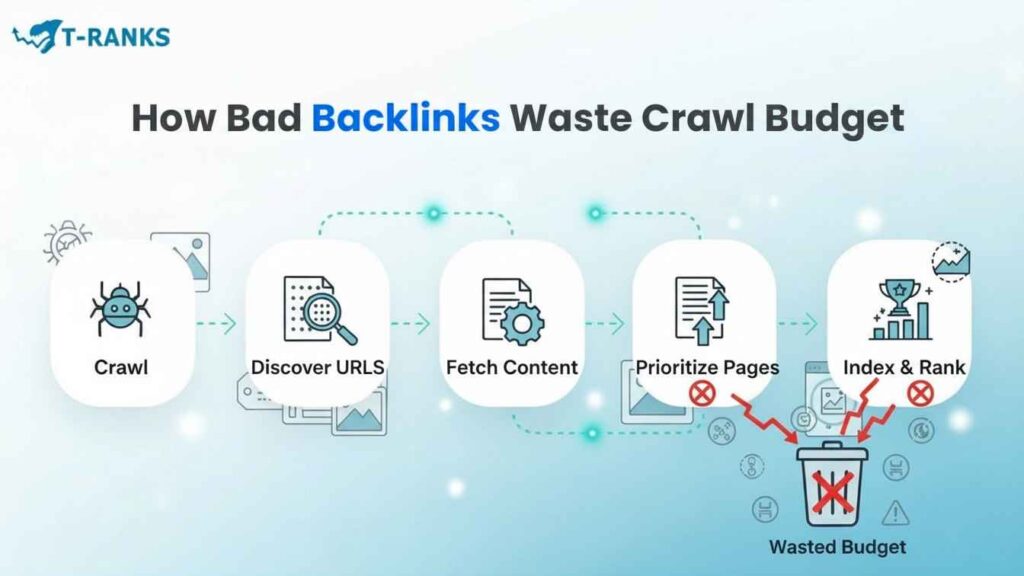
Bad backlinks waste crawl budget by pushing Googlebot toward URLs that offer little or no real search value. This happens during the crawling stage, before Google decides whether a page should rank or even be indexed.
Because crawling always comes before evaluation, Googlebot must first visit a URL to understand what it contains. When backlinks point to weak or broken pages, crawl budget is spent before Google can ignore those URLs.
Bad Backlinks Create Unnecessary Crawl Demand
Bad backlinks often come from spam comments, forum profiles, scraped pages, or automated link networks. These links introduce URLs that do not exist anymore, lead to thin content, or contain endless variations.
When Googlebot discovers these URLs through backlinks, it still attempts to crawl them. Each crawl request consumes part of the site’s limited crawl budget without producing indexing value.
Low-Value URLs Trigger Repeated Crawling
Once a low-value URL is discovered, it may be crawled again and again. When multiple backlinks point to the same broken or thin page, Googlebot may interpret this as ongoing activity.
This leads to repeated crawling of soft 404 pages, redirect chains, parameter-based URLs, or shallow content. Each revisit uses crawl budget that could have been used to refresh important pages or discover new content.
Important Pages Receive Less Crawl Attention
As unnecessary URLs compete for crawl time, important pages receive less attention. Googlebot works within strict time and resource limits for each site.
When crawl budget is consumed by junk URLs introduced through bad backlinks, key pages are crawled less frequently. This slows the discovery of new pages, delays updates to core content, and reduces search visibility long before any ranking loss becomes obvious.
Backlink Patterns That Commonly Waste Crawl Budget
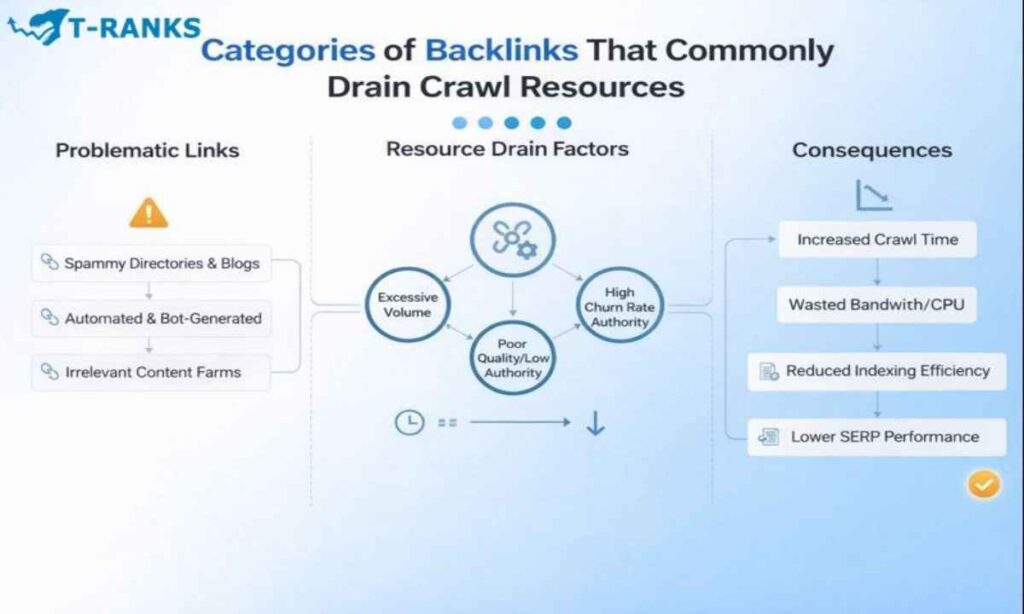
Not all bad backlinks waste crawl budget in the same way. Crawl waste usually comes from backlink patterns that repeatedly expose Googlebot to low-value or broken URLs.
Common examples include spam-generated links, automated link networks, and persistent sitewide links. These links often point to outdated paths, thin pages, or parameter-heavy URLs that require crawling but offer no indexing value.
Backlinks from compromised, non-indexed, or low-quality sites can also drain crawl resources. Googlebot must still crawl these URLs to assess their status, even when they never qualify for indexing.
The common issue across these patterns is persistence. When low-quality backlinks continue to surface the same weak URLs, Googlebot spends crawl time rechecking them instead of focusing on important pages. This is how backlink-driven crawl waste quietly accumulates over time.
How Googlebot Responds to Low-Quality Link Signals
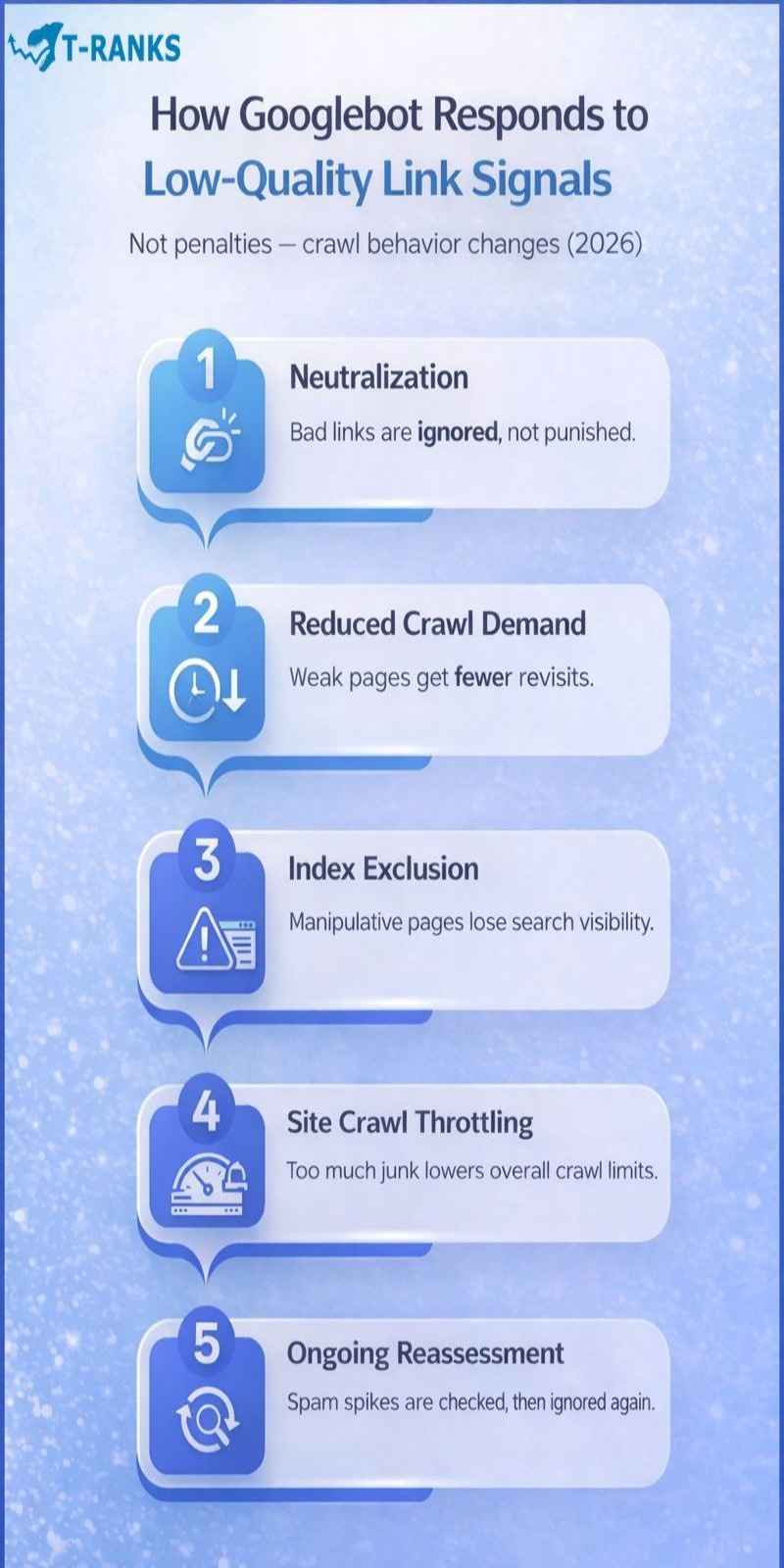
In 2026, Googlebot relies on advanced systems such as SpamBrain to understand link quality and patterns in real time. Instead of reacting with immediate penalties, Googlebot adjusts its crawling behavior based on how useful or manipulative those links appear.
These responses affect crawl activity first, often long before rankings or manual actions are involved.
Neutralization Without Immediate Penalties
In most cases, Googlebot neutralizes low-quality backlinks rather than penalizing a site. It may crawl a linked URL to understand its content, then ignore the link for ranking and authority purposes.
Even when a link is ignored, the initial crawl still happens. This means crawl budget can be used without producing long-term search value.
Changes in Crawl Frequency and Priority
Googlebot allocates more crawl attention to pages that appear useful, trusted, and actively maintained. Pages primarily supported by spammy, paid, or low-quality links signal weaker value.
Over time, these pages may be crawled less often. Updates take longer to be discovered, and crawl attention shifts toward other areas of the site or toward other websites entirely.
Indexing Limitations for Manipulative Patterns
When Google detects repeated or aggressive link manipulation, it may limit how certain pages are treated in the index. Some URLs may remain crawled but are excluded from search results.
Googlebot may still revisit these pages occasionally to check for changes, but they are no longer prioritized as active search content.
Site-Level Crawl Adjustments
If Googlebot repeatedly encounters junk URLs, hacked paths, thin pages, or endless redirects during crawling, it may reduce crawl limits for the site as a whole.
This protects Google’s resources but also means that important pages are crawled less frequently, even if those pages are high quality.
Continuous Reassessment of Link Activity
Link evaluation is ongoing. When Googlebot detects sudden spikes in low-quality backlinks, it may temporarily increase crawling to investigate the activity.
Once the pattern is identified as spam or low value, crawl frequency is reduced again. However, crawl budget has already been consumed during the evaluation phase.
These behaviors are often reflected in crawl statistics. Increased crawling of irrelevant URLs combined with reduced crawling of important pages usually indicates that Googlebot is responding to poor link quality or inefficient crawl paths.
.Common Crawl Budget Issues Caused by Bad Backlinks
Bad backlinks can create measurable crawl budget problems by repeatedly directing Googlebot toward low-value or broken URLs. These issues are technical, observable, and often appear at the crawl level long before rankings or traffic change.
The examples below show how backlink-driven crawl waste commonly appears in real site environments.
Crawl Traps Created by Spam URLs
Spam backlinks can pull Googlebot into endless URL paths. This often happens when links point to URLs that automatically generate new variations.
For example, a spam link may contain random parameters or date-based paths. When Googlebot follows the link, internal links can generate even more variations. The crawler continues exploring these paths instead of reaching important pages, consuming crawl budget without progress.
Index Bloat From Discovered Junk Pages
Bad backlinks can expose large volumes of low-value URLs that Googlebot must crawl before evaluation. Even if these pages are later excluded from the index, crawling still occurs.
Examples include backlinks pointing to tag pages, filter combinations, or internal search results. Large numbers of near-duplicate URLs are crawled, increasing crawl workload and reducing overall crawl efficiency over time.
Delayed Crawling of Important Pages
When crawl budget is wasted elsewhere, important pages are discovered and refreshed more slowly. This is one of the most damaging and least visible effects.
For example, a site publishes a new product or updates a core page while Googlebot is busy crawling spam URLs or rechecking broken paths introduced by bad backlinks. The update may take days or weeks to be discovered, reducing visibility in competitive results.
Redirect and Error Crawl Waste
Bad backlinks often point to old or deleted URLs that trigger redirects or errors. Googlebot still follows these links to verify where they lead.
A single backlink may hit an outdated URL that passes through multiple redirects before reaching a final page. Each hop requires a crawl request, and in some cases Googlebot stops before reaching the destination. This consumes crawl budget without improving indexing outcomes.
Reduced Crawl Speed Due to Crawl Stress
Large volumes of bad backlinks can indirectly reduce crawl capacity. When Googlebot encounters repeated errors while crawling junk URLs, it slows down to protect site stability.
If aggressive crawling triggered by spam links leads to timeouts or server errors, Googlebot may lower crawl speed across the entire domain. This limits crawl access to important pages even though the original issue started with bad backlinks.
Indicators That Backlinks Are Wasting Crawl Budget
Backlinks can waste crawl budget by pulling Googlebot toward low-value or unintended URLs instead of important pages. These signals usually appear in crawl behavior before rankings or traffic decline, making them useful early warning signs.
The indicators below help identify when backlinks are creating crawl inefficiencies.
Irrelevant URLs Appearing in Crawl Reports
Unexpected URLs showing up in crawl reports are often the first sign of backlink-driven crawl waste.
These URLs usually do not appear in sitemaps or internal links. Common examples include random parameters, outdated folders, hacked-style paths, or legacy URLs. Repeated crawling of these URLs suggests that external backlinks are influencing discovery.
High Numbers of Crawled but Not Indexed URLs
A growing count of crawled but not indexed URLs indicates crawl effort without indexing value.
Googlebot has already spent resources fetching these pages before deciding they are not suitable for search results. When many of these URLs share similar structures or come from external discovery, backlinks are often the source.
Crawl Activity Focused on Low-Value Pages
Crawl budget is misallocated when Googlebot frequently crawls low-value URLs instead of important pages.
This includes repeated crawling of 404 responses, redirect chains, thin tag pages, or parameter-heavy URLs. If priority pages are crawled infrequently while junk URLs receive attention, crawl competition is occurring.
Rising Crawl Volume Without Visibility Gains
An increase in crawl activity without growth in indexed pages or traffic suggests inefficient crawling.
This often happens after bursts of spam or automated backlinks introduce many URL variations. Crawl volume increases as Googlebot evaluates these URLs, but most are later discarded.
Delayed Crawling of New or Updated Content
Slow discovery of new or updated pages is a strong sign of crawl budget congestion.
When properly linked pages take days or weeks to be crawled, Googlebot’s crawl capacity is already being consumed elsewhere. Backlinks pointing to low-value URLs often divert attention during early discovery.
Why Backlink Related Crawl Waste Is Often Overlooked

Backlink-related crawl waste is often missed because it affects how Googlebot crawls a site long before rankings or traffic change. A website can appear stable while Googlebot quietly spends crawl budget on low-value URLs introduced through external links.
This happens because backlinks are usually reviewed for authority and penalty risk, not for their impact on crawl behavior. If rankings are stable and no penalty exists, backlinks are often assumed to be harmless, even when they repeatedly pull Googlebot toward thin, broken, or unnecessary pages.
The issue is also overlooked because crawl analysis and backlink analysis are rarely connected. Technical SEO focuses on crawl and indexing patterns, while off-page SEO reviews link profiles separately. Without linking backlinks to actual crawl paths, backlink-driven crawl waste often goes unnoticed until indexing slows or content freshness declines.
Crawl Budget Concerns for Small and Medium-Sized Sites
Crawl budget issues are often ignored on small and medium-sized websites because many people assume crawl limits only matter for large sites. In reality, Googlebot assigns a limited amount of crawl attention to every website, including small blogs, local businesses, and growing sites.
Smaller websites have less room for crawl waste. They receive fewer crawl visits overall, so when Googlebot spends time on low-value or unnecessary pages, important content may be crawled less often. This can slow indexing and delay updates in search results.
Bad backlinks can still distract Googlebot from important pages. Even a small number of low-quality links can lead the crawler toward broken or thin URLs. With limited crawl capacity, this distraction can quietly affect visibility before any ranking changes become noticeable.
How Google’s Spam Detection Changes Crawl Behavior Over Time
In 2025 and moving into 2026, Google’s spam detection does more than filter bad content. It gradually changes how Googlebot crawls a website over time. Instead of reacting only with penalties, Google adjusts crawl behavior based on patterns it observes.
Systems such as SpamBrain help Google identify low-quality signals during crawling. These systems look at overall behavior, not just individual pages or links.
Early Detection During Crawling
Googlebot can detect signs of low-quality or spam content as soon as it crawls a page. When a page shows clear spam signals, Google may still crawl it but decide not to index it.
Even though indexing is skipped, the crawl still happens. Over time, Google learns which areas of a site are unlikely to provide search value and reduces attention to them.
Gradual Changes in Crawl Priority
Google now adjusts crawl priority gradually. If a site repeatedly shows spam-like patterns, such as unnatural link growth or large numbers of thin pages, Googlebot may visit the site less often.
This does not happen all at once. Crawl frequency slowly decreases, which can delay the discovery and indexing of new or updated pages, even if those pages are legitimate.
Link Neutralization Without Immediate Penalties
A major shift in Google’s approach is link neutralization. Instead of penalizing sites for bad backlinks, Google often ignores those links when evaluating rankings.
However, Googlebot may still follow some of these links during discovery. Crawl budget can still be used before Google decides that the linked URLs are not worth further attention.
Crawl Adjustments Based on Site Stability
Googlebot also adjusts crawl behavior based on how a site responds during crawling. If repeated crawling of junk URLs leads to server errors or slow responses, Googlebot reduces crawl speed to protect the site.
This affects the entire domain, not just the problematic URLs, which can further slow crawling of important pages.
Recovery Happens Slowly Over Time
Spam detection is not permanent. When spam signals are cleaned up and crawl paths improve, Googlebot can slowly increase crawl activity again.
This recovery takes time. Google needs to see consistent improvements before restoring higher crawl frequency.
Monitoring Changes in Crawl Behavior
Changes in crawl behavior are often visible in Google Search Console. Increased crawling of error pages, parameter URLs, or low-value paths can signal spam-driven discovery.
A rising number of discovered but not indexed pages often means Googlebot found URLs but chose not to invest further resources in processing them.
Managing Crawl Waste Caused by Bad Backlinks

Managing crawl waste caused by bad backlinks is about reducing unnecessary crawl exposure, not aggressively fixing every link. The goal is to help Googlebot spend more time on valuable pages and less time exploring junk paths introduced through external links.
This section explains the principles behind managing crawl waste without turning it into a step by step technical process.
Monitoring Backlink Quality
Backlink quality matters beyond rankings because links influence how Googlebot discovers URLs. When backlinks point to broken, thin, or outdated pages, they can repeatedly trigger crawl activity with no indexing value.
Regular visibility into backlink patterns helps identify when external links are introducing low value URLs that compete for crawl attention, even if rankings remain stable.
Neutralizing Obvious Spam Signals
Google ignores many spam links automatically, but crawl discovery can still happen before those links are dismissed. Neutralizing obvious spam signals reduces repeated crawl attempts on junk URLs.
This includes minimizing exposure to non existent paths, duplicate URL patterns, and legacy pages that no longer serve a purpose. Clear signals help Googlebot learn which areas are not worth revisiting.
Protecting Crawl Paths
Protecting crawl paths means making it easier for Googlebot to reach important content without distraction. When crawl paths are clean, Googlebot naturally prioritizes high value pages.
By limiting access to low value URLs and reinforcing clear site structure, crawl budget is redirected toward pages that need frequent crawling and freshness, reducing the long term impact of bad backlinks.
Conclusion
Backlinks influence more than rankings. They shape how Googlebot discovers and crawls a website. Crawl budget is a limited Google resource, and when backlinks point to low-value, broken, or unnecessary URLs, crawl capacity is used before any ranking impact becomes visible.
Over time, this crawl inefficiency can slow indexing, reduce content freshness, and quietly weaken search visibility. Clean and relevant backlink profiles help Googlebot focus on important pages, leading to better crawl efficiency and more consistent discovery of valuable content.
Managing backlink-related crawl waste is an important part of long-term SEO. By understanding how backlinks influence crawling behavior, site owners can protect crawl budget, support faster indexing, and maintain stable search performance.
FAQs About Crawl Budget Backlinks
What is crawl budget in simple terms?
Crawl budget is the number of pages Googlebot is willing to crawl on a website within a given time. It exists because Google has limited resources and must prioritize which URLs to crawl first.
How do backlinks affect crawl budget?
Backlinks affect crawl budget by acting as discovery signals for Googlebot. When backlinks point to low-quality or unnecessary URLs, Googlebot may crawl them, using crawl resources that could have gone to important pages.
Can bad backlinks really waste Googlebot resources?
Yes, bad backlinks can waste Googlebot resources. They expose low-value or broken URLs that Googlebot must crawl before deciding they are not worth indexing.
Does Google crawl spam backlinks?
Yes, Googlebot may crawl URLs discovered through spam backlinks. Crawling often happens during early exploration, before trust and relevance signals are fully applied.
Do nofollow backlinks also waste crawl budget?
Yes, nofollow backlinks can still waste crawl budget in some cases. They can introduce URLs that Googlebot attempts to crawl even though they do not pass ranking signals.
How do broken backlinks impact crawl budget?
Broken backlinks waste crawl budget by sending Googlebot to 404 or non-existent URLs. Googlebot may revisit these URLs to confirm their status, consuming crawl resources each time.
What types of backlinks drain crawl budget the most?
Spam, auto-generated, and scraped backlinks drain crawl budget the most. These links often point to junk, thin, or parameter-heavy URLs with little or no indexing value.
Can toxic backlinks cause crawl budget issues without penalties?
Yes, toxic backlinks can waste crawl budget without causing penalties. Crawl inefficiency usually appears long before ranking drops or manual actions occur.
Are small websites affected by backlink-related crawl waste?
Yes, small websites are affected because their crawl allocation is limited. Even a small number of spam backlinks can consume a large share of crawl attention.
Does Google eventually stop crawling URLs from bad backlinks?
Yes, Google may reduce crawling as low-quality signals are recognized. However, new or persistent backlinks can keep triggering crawl attempts.
Is backlink-related crawl waste visible in Google Search Console?
Yes, backlink-related crawl waste can often be inferred from crawl patterns. Irrelevant URLs and high crawled-but-not-indexed counts are common indicators.
Should crawl budget be considered in backlink audits?
Yes, crawl budget should be considered in backlink audits. Backlinks that expose junk URLs can harm crawl efficiency even if rankings appear stable.