
Why do so many backlinks never help your website, even though SEO tools say they exist?
The reason is simple. Google never actually visits them.
A backlink only has value when Googlebot finds it and follows it to your site. Backlink tools can show where links are placed, but they cannot show whether Googlebot ever uses those links. Without a crawl, a link cannot pass trust, authority, or discovery signals, no matter how strong it looks in reports.
This is where most link building assumptions fall apart. What appears valuable on paper often has no real impact in practice.
Log file link analysis solves this problem by revealing real Googlebot behavior. Server logs record every time Googlebot reaches your site and exactly where it came from. This makes it possible to see which backlinks truly work and which ones are silently ignored.
In this article, you’ll learn what log file link analysis is, how Googlebot actually discovers links, and why backlink tools alone are not enough. You’ll also learn how to confirm working backlinks, uncover hidden links, and improve link building decisions using real crawl data instead of estimates.
What Log File Link Analysis Is in SEO
Log file link analysis is the process of using server log data to confirm how search engine crawlers actually discover and crawl backlinks to your website.
It validates backlinks based on real crawl activity rather than reported or inferred link existence from third-party tools.
In SEO, a backlink only becomes meaningful after it is crawled. Log file link analysis exists to answer one critical question: did the search engine actually reach your site through this link?
Let me explain this with a real example to make the concept clearer.
During a backlinks audit at T-RANKS for our client, I reviewed a site that showed several high-authority backlinks in popular SEO tools. On paper, those links looked strong. However, when I checked the server logs, Googlebot had never reached the site through most of those URLs. There were no referrer entries, no crawl timestamps, and no evidence that the links were ever followed.
At the same time, the logs revealed a different external page, one that did not appear in backlink tools at all, consistently sending Googlebot to the site. That link was actively driving crawl discovery, even though it was invisible in traditional reports. This is the difference between a reported backlink and a crawl-confirmed backlink.
To understand why this happens and how log file link analysis makes these differences visible, it helps to look at how server logs record crawl activity and what that data reveals about real search engine behavior.
How Server Logs Capture Real Googlebot Crawl Data
Server logs are raw records generated by your web server every time a request is made. When Googlebot visits your site, the interaction is recorded automatically.
Each log entry includes the requested page, the response status, and the referrer URL. The referrer shows the exact external page Googlebot visited before landing on your site. This creates direct, timestamped proof that a backlink was followed.
Because log files are first-party data, they capture every crawl without sampling, delay, or interpretation. Nothing is estimated, and nothing is inferred.
Why Log Files Reflect Actual Search Engine Behavior
Log files reflect real search engine behavior because they record decisions that have already been made. They show which links Googlebot chose to follow after applying its internal priorities.
Search engines do not crawl every link they discover. They evaluate relevance, trust, crawl limits, and page quality before deciding whether a link is worth visiting. These decisions are invisible in backlink tools but fully visible in log data.
If a backlink triggers a crawl, it appears in the logs.
If it does not, the link remains unvalidated.
This makes log files the most accurate source for understanding which backlinks are part of the active crawl graph.
What Log File Link Analysis Reveals Beyond Link Existence
Log file link analysis does more than confirm whether a link was crawled. It reveals how crawl activity enters and moves through your site.
Logs show which backlinks act as entry points, which pages Googlebot reaches next, and where crawl paths stop. This helps identify pages that receive link equity and pages where crawl flow breaks down due to poor structure, redirects, or errors.
This level of visibility is not possible with backlink reports alone.
Brief Contrast With Traditional Backlink Analysis
Traditional backlink analysis focuses on link presence. Tools crawl the web and report links they find, along with authority metrics and anchor text.
Log file link analysis focuses on link behavior. It confirms whether a crawler actually followed the link and reached your site.
A backlink can appear strong in a tool but provide no SEO value if it is never crawled. Log analysis separates reported links from crawl-confirmed links, which is essential for accurate evaluation.
Why This Definition Matters for Modern SEO
Search engines increasingly rely on crawl behavior to assess trust, relevance, and discovery. Links that do not trigger crawls cannot reliably influence visibility or rankings.
Log file link analysis provides the factual foundation needed to evaluate backlinks correctly. It replaces assumptions with evidence and ensures link-building decisions align with how search engines actually operate
How Googlebot Discovers Links Through Crawling

Googlebot discovers links by starting from URLs it already knows and following hyperlinks across the web. As it moves from page to page, each crawl request is recorded in server logs, including referrer information that shows where discovery originated. This makes log data the most reliable way to trace how backlinks actually lead Googlebot to your site.
To understand how backlinks become part of the crawl process, it helps to look at how Googlebot discovers and evaluates links step by step.
Step-by-Step Process of How Googlebot Discovers Links
Googlebot starts with known pages
Googlebot begins crawling from URLs it already knows. These come from its existing index, previous crawl cycles, and submitted sitemaps. This known set of pages forms the starting point for discovering new links across the web.
Googlebot fetches and processes a page
When Googlebot requests a page, it downloads the HTML content. If the page relies on JavaScript, Googlebot may render the page to expose links that are not visible in the raw source. This allows link discovery to reflect how real users experience the page.
Links are extracted from the page
Googlebot scans the processed page and identifies crawlable links, typically standard hyperlinks pointing to other URLs. Each extracted link becomes a potential candidate for crawling, but discovery alone does not guarantee a visit.
Discovered URLs are evaluated and queued
Before crawling a discovered URL, Googlebot evaluates it. Factors such as the importance of the source page, topical relevance, freshness, and available crawl capacity determine whether the URL is added to the crawl queue or ignored.
Googlebot follows a backlink to your site
When a backlink meets crawl priority thresholds, Googlebot visits the target URL on your website. This is the moment a backlink moves from simple existence to active crawl participation.
Your server records the referrer URL
When Googlebot reaches your site, your server logs the request. If a referrer header is present, the log entry records the exact external page Googlebot came from. This provides timestamped, verifiable proof that a backlink was followed.
Crawling continues internally
After landing on your page, Googlebot extracts internal links and may continue crawling additional pages on your site. The strength of your internal linking determines how far crawl activity extends beyond the initial entry page.
Before evaluating backlinks individually, it’s important to understand the broader way search engine crawlers discover links across the web, because this context explains why certain links gain priority over time.
How Search Engine Crawlers Discover Links on the Web
Search engine crawlers discover links by repeatedly crawling known pages and expanding outward through outgoing links. Over time, this process builds a connected web graph that allows search engines to find new content and revisit existing pages based on priority and relevance.
Discovery is driven by several signals, including frequently crawled authoritative pages, recently updated content that triggers recrawls, sitemap-listed URLs, and previously crawled pages that are revisited to detect changes.
This general discovery process becomes especially important when analyzing how external backlinks introduce search engines to your site.
Role of Referrer URLs in Link Discovery and Crawl Paths
Referrer URLs show the page Googlebot visited immediately before requesting your page. In log file analysis, the referrer field directly connects a crawl event to a specific backlink source.
Referrer data allows you to confirm which external page triggered discovery, identify pages that act as repeated crawl entry points, and detect backlinks that tools did not report but Googlebot actually followed.
A crawl path begins when Googlebot visits a page on another website, discovers your link, and then follows it to your site. That external page becomes an entry point into your site’s crawl graph. Some backlinks create strong crawl paths because their source pages are revisited often, while others create weak or one-time paths that stop after the initial visit.
Not every crawl includes a referrer. Some visits originate from internal navigation or system-driven crawling, which is why referrer data should always be interpreted alongside other crawl signals.
Why Discovery Paths Matter for Link Evaluation
Discovery paths show how backlinks perform based on real crawler behavior. A backlink that repeatedly brings Googlebot to your site is typically more valuable than one that is rarely or never followed.
These paths also expose crawl inefficiencies, such as entry pages that redirect or return errors, crawl paths that stop early due to weak internal linking, and valuable backlinks pointing to low-priority or poorly connected pages.
By understanding discovery paths, backlinks can be evaluated based on behavior rather than appearance. This naturally leads into the next section on why backlink tools alone cannot validate link value.
Why Backlink Tools Alone Cannot Validate Link Value
Backlink tools like Ahrefs, Semrush, and Majestic are widely used across the SEO industry, and for good reason. They are excellent at discovering links and providing directional metrics that help SEOs understand link landscapes at scale. However, relying on tool data alone is not enough to validate real backlink value.
Every experienced SEO eventually reaches the same point. To move beyond surface-level analysis, you have to stop asking what tools report and start asking how search engines actually behave. That shift requires analytical judgment, deeper investigation, and evidence that third-party tools simply cannot access.
At T-RANKS, we do not treat backlink tools as a source of truth. We use them as a starting point. From there, we validate links using crawl data, behavioral patterns, and server-side evidence to determine which backlinks genuinely influence discovery, trust, and rankings.
To understand why this extra validation layer is necessary, it helps to look at what backlink tools can and cannot actually measure.
What Backlink Tools Report
Backlink tools crawl large portions of the public web, extract hyperlinks, and compile metrics such as domain ratings, anchor text, link age, and estimated traffic value. For example, a tool may report thousands of backlinks pointing to a site, suggesting strong authority growth.
However, this data only reflects what the tool’s crawler detected. It does not confirm whether Google followed those links, evaluated their context, or incorporated them into its crawl graph. Tool data is based on proprietary indexes that are updated periodically and often rely on sampling rather than real-time interaction with your server.
Why Many Reported Links Are Never Crawled
A significant portion of tool-reported links are never crawled by search engines. This happens because Google applies strict prioritization before following links.
Common reasons links go uncrawled include nofollow attributes, JavaScript rendering limitations, robots.txt restrictions, low crawl priority, or crawl budget limits on large sites. Links placed on noindex pages, orphaned pages, login-restricted areas, or content Google considers low value are also frequently ignored.
Backlink tools cannot simulate these crawl decisions because they do not have access to server-side crawl data.
Difference Between Discovered, Crawled, and Indexed Links
A discovered link is a link that exists on a page and is detected by a backlink tool.
A crawled link is one that Googlebot actually follows and reaches the target page.
An indexed link is a crawled page that is processed and added to Google’s index.
The funnel narrows quickly. Many discovered links never reach the crawled stage, and only a smaller portion are indexed. Because backlink tools stop at discovery, they often overestimate real link value.
Why Crawl Confirmation Is Critical for Link Quality
In 2026, links that are never crawled pass no meaningful authority because Google never evaluates their context, freshness, or equity flow.
Server logs provide the most reliable validation layer. They show which backlinks trigger crawls, how often they are used, and how crawl paths move through your site. This makes it possible to separate cosmetic backlinks from those that actively influence search engine behavior.
Validating Backlinks Using Log File Data
Validating backlinks means confirming whether Google actually uses those links to reach your site. Instead of relying on what tools report, this process uses server logs to verify real Googlebot activity.
In simple terms, a backlink only has SEO value if it triggers a real crawl. If Googlebot never follows the link, it does not meaningfully contribute to discovery, authority, or rankings.
The steps below explain how to validate backlinks using log file data in a practical and repeatable way.
Step-by-Step Backlink Validation Process
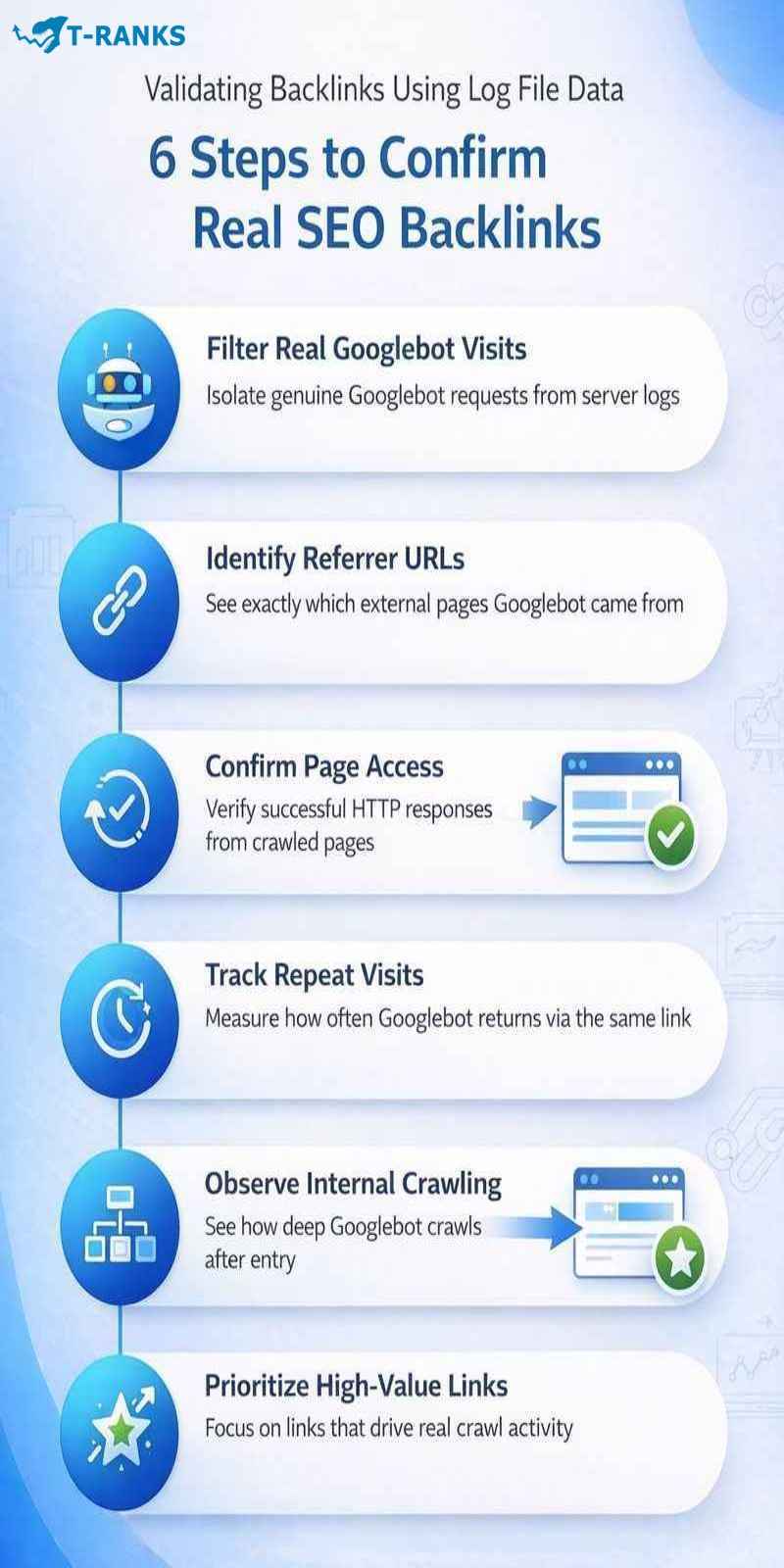
Step 1: Focus Only on Real Googlebot Visits
Every website server keeps a record of visits in files called server logs. These logs list who visited your site, which page was requested, and where the visitor came from.
For backlink validation, the first step is to look only at visits made by Googlebot. This means separating genuine Google crawler requests from human visitors, scrapers, and fake bots.
In practice, this is done by filtering log entries that identify themselves as Googlebot and originate from Google-owned IP ranges. Many log analysis tools handle this automatically, but the goal is simple. You want to see only real Google crawling behavior before analyzing backlinks.
Step 2: Identify Where Googlebot Came From
Once Googlebot traffic is isolated, the next step is to examine the referrer field in the logs. The referrer shows the page Googlebot visited immediately before landing on your site.
These referrer URLs represent the exact external pages whose links Googlebot actually followed. Matching these URLs against backlink tool reports helps confirm which reported links are real crawl entry points and which exist only on paper.
Step 3: Confirm the Page Was Successfully Reached
After identifying referrers, review the HTTP status codes for the pages Googlebot reached through those links.
A consistent pattern of successful responses confirms that the backlink delivered Googlebot to a live, accessible page. If a link appears in a backlink tool but never produces Googlebot visits in your logs, it has not influenced crawl behavior.
Step 4: Observe How Often Googlebot Returns
Next, review how frequently Googlebot arrives from each referrer over time. Some backlinks trigger only a single visit, while others repeatedly bring Googlebot back to your site.
Repeated visits indicate that Google considers the source page stable and worth revisiting. These links tend to carry more practical value than links that trigger one-time crawls.
Step 5: Check What Happens After Entry
After Googlebot lands on your site, examine how far it continues crawling internally. This shows whether the backlink supports deeper discovery or stops at the entry page.
Backlinks that lead to deeper internal crawling usually indicate stronger influence than those that result in shallow or stalled crawl paths.
Step 6: Prioritize Backlinks Based on Real Behavior
Finally, group backlinks based on what the logs show. Links that consistently drive entry and deeper crawling should be treated as high-value assets.
Links that are rarely crawled or lead nowhere internally should be deprioritized, regardless of how strong they appear in backlink tools.
Identifying Backlinks Googlebot Ignores
Log file analysis also reveals backlinks that appear in reports but do not trigger real crawl activity. These links show little or no referrer presence in server logs, indicating that Googlebot is skipping them.
Common causes include nofollow attributes, weak topical relevance, low-trust source pages, or pages Google rarely revisits. Identifying these links helps remove false positives from backlink audits.
Using Crawl Frequency as a Quality Signal
Crawl frequency reflects how much attention Googlebot gives to a backlink source. When a referrer repeatedly delivers Googlebot to your site, it suggests the source is considered relevant and stable.
When repeated visits are paired with deeper internal crawling, the backlink is more likely contributing to authority flow and site discovery.
Why Crawl Frequency Should Not Be Used Alone
Crawl frequency must be interpreted carefully. Some low-quality pages may trigger shallow crawls without passing real value, while highly relevant niche links may be crawled less often but still matter.
For accurate validation, crawl frequency should be evaluated alongside relevance, linking page quality, anchor context, and internal linking behavior. Together, these signals provide a reliable framework for determining true backlink value.
Finding Hidden and Unreported Backlinks Using Logs
Hidden or unreported backlinks are external links that Googlebot actually follows to reach your site but never appear in backlink tools like Ahrefs or Semrush. These links exist, influence crawling, and sometimes pass value, yet remain invisible to third-party crawlers.
This usually happens because many parts of the web are inaccessible to SEO tools. Private forums, gated communities, noindex pages, recently published content, or sites that block tool crawlers can still be discovered by Googlebot. When that happens, these links appear only in your server logs as referrer URLs.
Some hidden backlinks are beneficial because they introduce real crawl discovery from relevant sources. Others may be harmful if they originate from spam networks or low-quality pages. Log file analysis allows these links to be evaluated based on real Googlebot behavior rather than assumptions.
How to Uncover Hidden Backlinks Using Referrer URLs
Step 1: Look for Referrers You Don’t Recognize
Server logs record where Googlebot came from before landing on your site. By isolating Googlebot traffic and reviewing referrer URLs, you can identify external pages that sent Googlebot to your site.
Compare these referrers against your backlink tool reports. Any external source appearing in logs but missing from tools represents a hidden or unreported backlink.
Step 2: Identify Which Hidden Links Actually Matter
Not every hidden backlink is valuable. The next step is to observe behavior, not just presence.
Focus on external referrers that repeatedly send Googlebot to your site or initiate deeper internal crawling. These patterns indicate that the source page is revisited by Google and acts as a meaningful crawl entry point rather than a one-time accident.
Step 3: Validate the Source and Crawl Impact
Export the identified referrer URLs into a simple list and review them manually or alongside Google Search Console data.
High-value hidden backlinks typically lead to additional crawling beyond the landing page. Low-quality sources usually result in shallow or irregular crawl activity that stops quickly.
When External Pages Drive Crawls Without Being Indexed
Some external pages that send Googlebot traffic are not indexed or visible in search results. These pages may use noindex directives, restrict SEO tool crawlers, or exist behind partial access controls.
Even so, Googlebot can still encounter their links through other discovery paths. Server logs capture this activity, revealing crawl behavior that backlink tools cannot see.
Why Hidden Backlinks Still Matter for SEO
Hidden backlinks matter because Googlebot behavior determines real SEO value. If a link introduces your pages into Google’s crawl queue and supports further internal discovery, it contributes to authority flow regardless of whether tools report it.
By identifying beneficial hidden links, neutralizing risky ones, and strengthening internal paths from these entry points, you can improve crawl efficiency and uncover link equity that traditional backlink analysis consistently misses.
Identifying Orphan Backlinks and Lost Link Equity
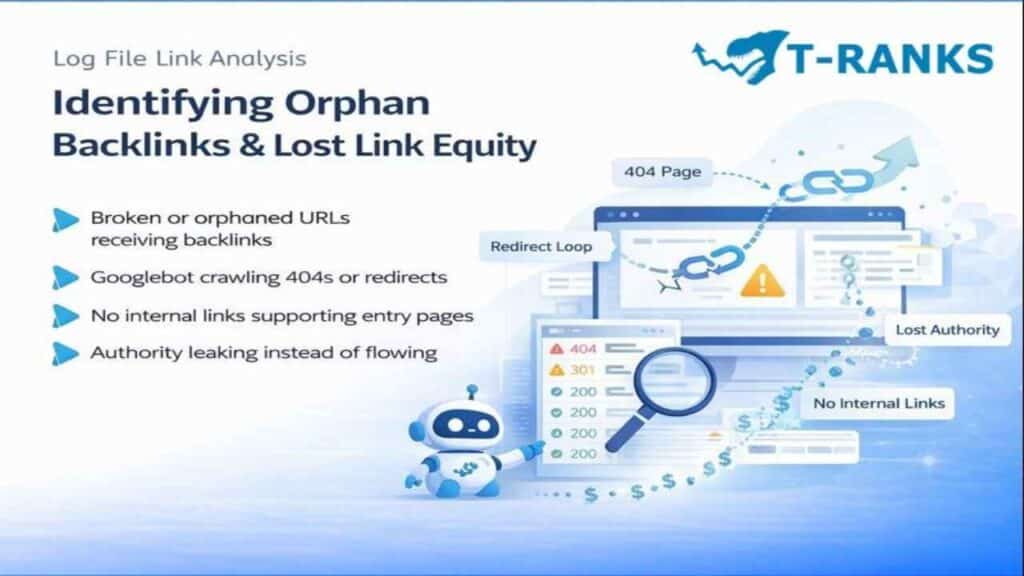
Orphan backlinks and lost link equity are high-value SEO issues that often go unnoticed when relying only on backlink tools. Log file analysis exposes these problems clearly by showing how Googlebot actually reaches broken, redirected, or internally disconnected pages, revealing where authority is leaking and how it can be recovered.
What Are Orphan Backlinks?
Orphan backlinks are external links pointing to pages on your website that lack proper internal connections or no longer function as intended. These pages may return a 404 error, sit behind unnecessary redirects, or exist without any internal links pointing to them.
Even if Googlebot discovers these pages through external links, the absence of internal support signals low importance, causing the passed authority to weaken or stop entirely.
Practical Step-by-Step: Finding Orphan Backlinks
Filter Logs for Errors
Start by filtering your server logs for verified Googlebot requests that return non-200 status codes, especially 404 and repeated 301 responses. These entries immediately highlight pages where link equity cannot flow correctly.
Map the Damage
Extract the referrer URL and the broken target URL from the logs. This shows exactly which external pages are sending Googlebot to invalid or poorly routed destinations on your site.
Quantify the Loss
Measure how often Googlebot hits each broken or orphaned page. URLs receiving frequent crawl attempts indicate valuable backlinks that deserve immediate attention.
Cross-Check Internal Links
Compare the URLs found in logs against your internal crawl data. Any page appearing in logs but missing from your internal link structure is a confirmed orphan that relies entirely on external discovery.
How Logs Expose Lost Link Equity
Lost link equity occurs when Googlebot reaches a URL that cannot pass authority forward due to errors or weak routing. Log files expose this by showing repeated crawl attempts that fail to resolve into meaningful site exploration.
When a strong external referrer consistently sends Googlebot to a dead or isolated page, the authority from that backlink effectively disappears instead of strengthening your site.
Reclamation Opportunities and Fixes
Log-driven insights make link reclamation straightforward and low risk:
- Restore the original page if it still matches search intent
- Apply a clean 301 redirect to the most relevant live page
- Strengthen internal linking from the recovered target to key sections
- Contact linking sites to update outdated URLs when appropriate
By using log file data, orphan backlinks stop being hidden technical issues and become clear recovery opportunities, allowing you to reclaim lost authority and improve crawl efficiency with minimal effort.
Using Log File Insights to Improve Link Building Strategy
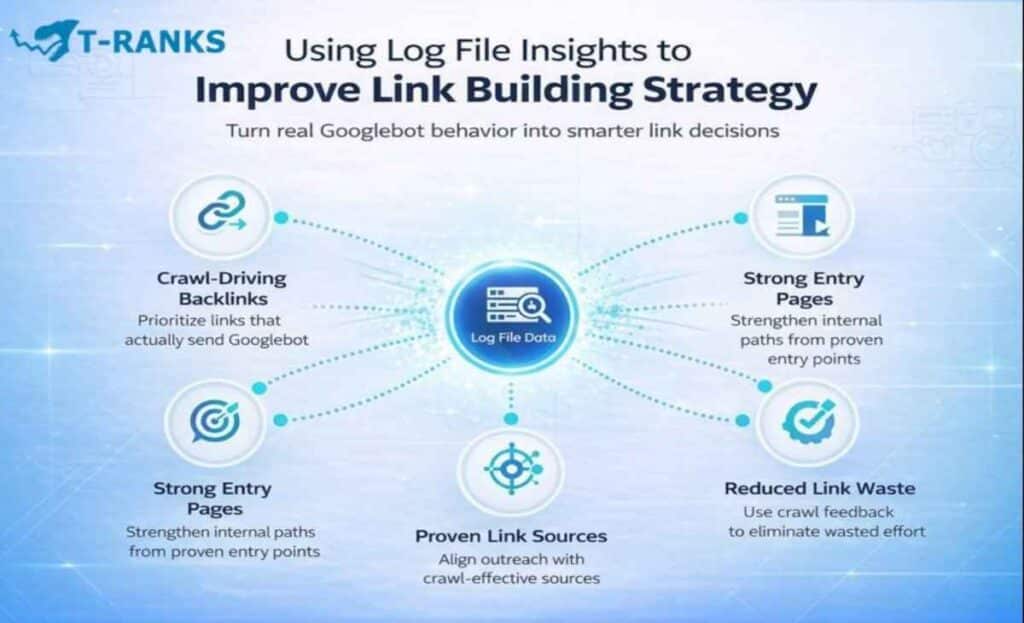
Log file insights change how link building decisions are made. Instead of relying on reported metrics alone, they show which backlinks Googlebot actually follows and uses to discover your site.
This allows link building efforts to be guided by real crawl behavior rather than assumptions, helping you focus resources where they produce measurable impact.
Below are the most effective ways to improve link building strategy using log file data.
Prioritize Backlinks That Actually Drive Crawl Activity
Many backlinks appear valuable in tools but never trigger a Googlebot visit. These links exist, but they do not contribute to discovery or crawling.
Log files reveal which external pages actively send Googlebot to your site. These backlinks have already passed Google’s initial relevance and trust filters, making them far more reliable indicators of real value.
Focusing on crawl-driving links shifts link building from quantity-driven to behavior-driven and helps eliminate effort spent on placements that never influence search engines.
Strengthen Internal Paths From Proven Entry Pages
Some pages receive repeated Googlebot visits because they are linked from strong external sources. These pages act as crawl entry points into your site.
If those entry pages are poorly connected internally, crawl value stops there. Log file data makes it easy to identify where Googlebot enters most often and whether it continues crawling deeper.
By improving internal links from these entry points, you guide crawl activity toward high-value pages and prevent external link value from being trapped on a single URL.
Align Link Acquisition With Proven Crawl Behavior
Log file data reveals patterns in how Googlebot prefers to discover your site. Certain site types, content formats, and link placements consistently trigger crawling, while others rarely do, even if they look strong in tools.
Using this insight, link acquisition can be aligned with sources that already demonstrate crawl effectiveness. Targeting similar sites and placements increases the likelihood that new links will be discovered quickly and reused over time.
This approach improves discovery speed and reduces dependence on speculative link placements.
Reduce Link Building Waste Using Crawl Feedback
Log file insights provide direct feedback on link building performance after links go live. Instead of waiting for ranking changes, you can see whether Googlebot interacts with new links at all.
By monitoring crawl response, you can identify which sources trigger fast discovery, which links are ignored, and where outreach strategies need adjustment.
Over time, this creates a link building process that improves with each campaign rather than repeating the same assumptions.
Why This Approach Works
Search engines rely on crawl behavior to discover, evaluate, and prioritize links. Log files provide direct visibility into that behavior.
By prioritizing crawl-driving backlinks, strengthening internal paths, and aligning acquisition with crawler behavior, link building becomes focused on links that actually influence discovery and rankings, not just links that look strong in reports.
Practical Workflow for Log File Link Analysis
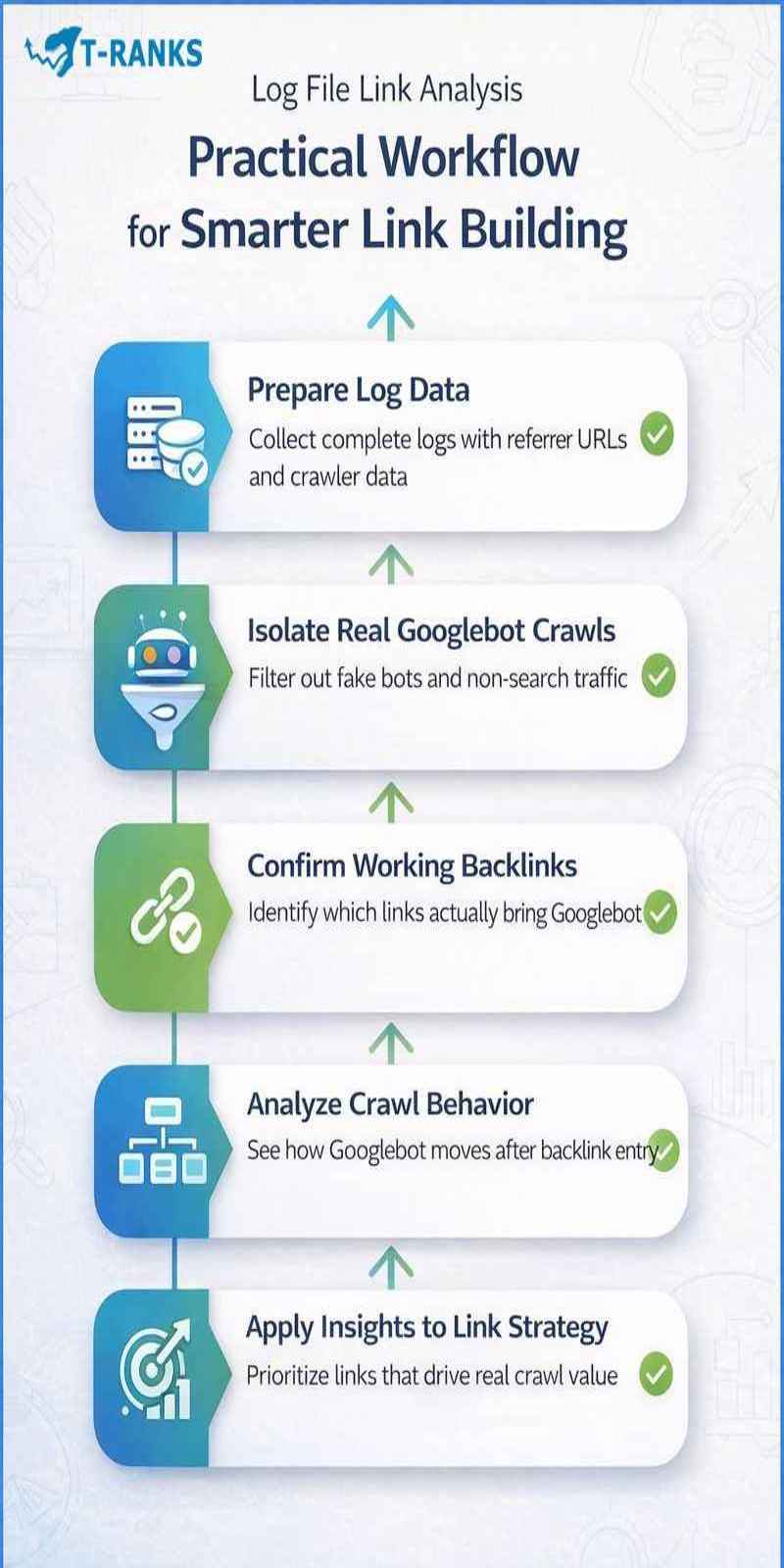
A practical workflow ensures log file analysis leads to measurable improvements in link building, not just technical observations. The goal is simple. Confirm which backlinks actually work, identify where link value is lost, and use real crawl behavior to guide smarter link building decisions.
The workflow below is designed specifically for SEO teams and link builders. It focuses on clarity, repeatability, and real-world application.
Step 1: Prepare Log Data With a Clear Link Focus
Log file analysis should always start with intent. You are not collecting logs to audit servers. You are collecting logs to understand how search engines reach your site through links.
For backlink analysis, logs should:
- Cover periods when backlinks were actively built or changed
- Include referrer URLs and crawler identification
- Represent a consistent and recent time window
- Be complete and unsampled
Logs that do not include referrer data or crawler signals cannot support backlink validation.
Step 2: Isolate Genuine Googlebot Crawl Activity
Raw logs contain noise. Automated scripts, fake bots, uptime monitors, and internal tools can distort crawl patterns if not removed.
This step ensures that:
- Only real Googlebot activity is analyzed
- Crawl behavior reflects search engine decisions
- Backlink validation is based on trusted data
Without proper isolation, crawl frequency and backlink impact are easily misinterpreted.
Step 3: Confirm Which Backlinks Actually Work
This is where log file analysis becomes a link building tool.
From verified Googlebot visits, extract:
- External referrer URLs that led Googlebot to your site
- Target pages that received crawler visits
- Response status to confirm pages are accessible
- Timing and repetition of crawler arrivals
This step answers the most important link building questions:
- Which backlinks are actually followed?
- Which reported links are ignored?
- Which pages act as crawl entry points?
- Which sources trigger repeated discovery?
Only links confirmed here should be treated as active backlinks.
Step 4: Analyze Crawl Behavior After Backlink Entry
Backlink value depends on what happens after Googlebot arrives.
Once Googlebot lands on a page through a backlink, internal structure determines whether crawl activity spreads or stops. At this stage, review:
- Which internal pages are crawled after entry
- How far Googlebot travels from the landing page
- Whether important pages are reached
- Where crawl paths terminate early
This reveals whether backlinks support site-wide visibility or remain isolated.
Step 5: Turn Crawl Patterns Into Ongoing Link Strategy
The final step is applying insights to link building decisions.
Based on crawl behavior, actions often include:
- Fixing broken or redirected pages that still receive crawler visits
- Improving internal linking from strong entry pages
- Prioritizing link sources that consistently drive crawl
- Adjusting outreach targets based on crawl response
- Reclaiming link equity that already exists but is poorly routed
Log file analysis should not be a one-time audit. When used regularly, it becomes a validation system for link building, helping teams review new links, assess campaign impact, and reduce risk over time.
Common Mistakes in Log File Link Analysis

Log file analysis provides direct insight into how search engines interact with links, but misinterpretation can quickly lead to poor SEO decisions. Avoiding these common mistakes ensures log data improves link building outcomes instead of creating false confidence.
1. Confusing crawl activity with indexation
Crawl activity does not mean a page is indexed or contributing to rankings. Googlebot visits recorded in logs only confirm access, not eligibility for search results.
A frequent mistake is assuming that high crawl frequency signals success, especially when thin or duplicated pages are crawled but later excluded from the index.
Index status must always be reviewed separately before judging link value.
2. Ignoring referrer data
Focusing only on which pages were crawled misses the core purpose of log file link analysis. Referrer data shows where Googlebot came from and which backlinks actually triggered discovery.
Ignoring referrer URLs hides the real sources of crawl activity and turns log analysis into a technical report instead of a link validation process.
External referrers should always be reviewed first.
3. Over focusing on volume instead of behavior
High crawl volumes can be misleading. A large number of crawler hits does not automatically indicate strong link value.
A smaller number of deep, repeated crawls from relevant sources often provides more SEO benefit than thousands of shallow visits from weak or unrelated sites.
Entry points, crawl depth, and repeat discovery matter more than raw hit counts.
4. Drawing conclusions without SEO context
Log data shows how crawlers move, not why rankings improve or decline. Interpreting crawl patterns without SEO context often leads to incorrect conclusions.
A frequently crawling referrer may represent a strong authority source or a low-quality automated site. Without evaluating relevance, content quality, internal linking, and indexability, log data alone can be misleading.
Log file analysis must always be combined with broader SEO signals.
Bonus pitfalls to avoid
Unverified bots
Not every crawler claiming to be Googlebot is legitimate. Including fake or automated bots inflates crawl data and distorts backlink validation. Always ensure only genuine search engine crawlers are analyzed.
Short timeframes
Very short log windows rarely show reliable patterns. Crawl behavior fluctuates daily, so using longer time periods helps identify consistent trends rather than temporary spikes.
No historical baseline
Without historical log data, it is difficult to tell whether crawl changes reflect real improvement or normal variation. Comparing current data with past behavior is essential for accurate interpretation.
When Log File Link Analysis Is Worth the Effort

Log file link analysis is most valuable when crawl behavior directly influences visibility, link performance, or return on investment. It is not a requirement for every website, but in the situations below it becomes a high-impact SEO practice rather than an optional add-on.
Large websites
Large websites face crawl limitations that smaller sites rarely encounter. When a site contains thousands of URLs, Googlebot becomes selective about what it crawls, how often it revisits pages, and where crawl activity is spent.
Log file analysis is worth the effort for large sites because it helps:
- Identify which backlinks actually bring Googlebot into priority sections
- Detect crawl budget waste on low-value or duplicate URLs
- Confirm whether important pages are being discovered and revisited consistently
For ecommerce platforms, large publishers, and programmatic SEO sites, logs often provide the only reliable view of real crawl priorities at scale.
High cost or aggressive link building campaigns
When link building requires significant investment, relying on assumptions becomes risky. High-authority placements, digital PR campaigns, and competitive outreach strategies all need validation beyond third-party metrics.
Log file link analysis is justified in these campaigns because it allows teams to:
- Confirm whether Googlebot actually follows newly acquired backlinks
- Identify links that exist but never trigger crawl
- Reduce wasted spend on sources that look strong in tools but deliver no crawl response
For aggressive or expensive link building efforts, log data acts as proof of performance rather than estimated value.
Agency and enterprise SEO workflows
Agencies and enterprise SEO teams operate at scale and need defensible, repeatable processes to support decisions. Log file link analysis strengthens these workflows by replacing assumptions with crawl-confirmed evidence.
It helps by:
- Validating backlink performance across large sites or multiple clients
- Explaining why certain link sources outperform others
- Supporting strategic recommendations with first-party crawl data
- Reducing reliance on sampled or third-party metrics alone
For agencies, this improves reporting credibility. For enterprises, it supports governance, consistency, and long-term optimization across complex sites.
Final takeaway
Log file link analysis is worth the effort when scale, cost, or complexity makes crawl behavior a deciding factor. In these situations, it provides clarity that tools alone cannot and turns link building from assumption-based activity into crawl-validated strategy.
Future Considerations: AI Crawlers and Link Discovery
The way links are discovered and evaluated is changing. As AI-driven systems and large language models increasingly interact with web content, link discovery is no longer based only on crawling paths between pages. It is becoming more selective, context-aware, and intent-driven.
These changes do not replace traditional search crawlers, but they add a new layer to how links, sources, and authority are interpreted. Log file data plays an important role in understanding this shift because it captures how these systems actually access websites.
From Path-Based Crawling to Intent-Based Discovery
Traditional search crawlers discover links by following URLs sequentially and building an index of pages. AI-driven systems behave differently.
Instead of mapping entire sites, AI crawlers often focus on specific passages, entities, or sections that align with a given topic or question. A link is valued less for its position in a crawl path and more for the context in which it appears.
This means links embedded in relevant, well-structured content are more likely to be discovered and reused than links placed solely for navigation or visibility.
Contextual Evaluation Replaces Simple Link Signals
AI systems use natural language understanding to interpret why a link exists. Rather than treating a backlink as a simple signal of popularity, they evaluate how it contributes to topical relevance and subject authority.
Links increasingly act as connectors between entities and ideas rather than just pages. This makes contextual placement and surrounding content more important than raw link counts.
Log data helps reveal which sources AI systems repeatedly reference or retrieve, offering insight into which links are being treated as meaningful signals.
Predictive Crawling and Selective Retrieval
Advanced AI crawlers often estimate the potential value of a source before retrieving it. These decisions are influenced by historical behavior, domain trust, and content quality signals.
As a result, not every link is followed, even if it is technically accessible. This makes discovery patterns less predictable and reinforces the importance of understanding actual crawl behavior rather than assumptions.
Log files provide early visibility into which sources are being requested and reused by AI-driven systems over time.
Emerging Standards for AI Access and Control
As AI discovery expands, new technical standards are emerging to guide how AI systems interact with websites.
One example is the use of an llms.txt file, which can be placed at the root of a site. This file is designed to highlight high-value resources and structured summaries intended for AI retrieval and citation rather than traditional indexing.
Many sites are also beginning to differentiate between search crawling and AI usage, allowing search engine bots while selectively limiting AI training or retrieval access.
The Shift Toward Zero-Click Link Value
As AI assistants increasingly provide complete answers directly in search interfaces, the role of links is changing.
Links are no longer valued only for the traffic they send. Being cited as a trusted source within AI-generated summaries or overviews has become a new form of visibility and authority.
These interactions often appear in logs as AI-driven retrieval requests rather than traditional crawl patterns, making log analysis essential for understanding this form of exposure.
Infrastructure Implications for AI Crawlers
AI-driven crawlers introduce new technical considerations for websites.
They can place heavier demands on servers by retrieving larger content segments and executing JavaScript more effectively than older bots. This allows them to discover links embedded within interactive or dynamic elements that traditional crawlers may miss.
Log data also reveals that AI systems sometimes request URLs that do not exist, based on predicted patterns rather than actual links. This increases the importance of clean site structure, proper error handling, and disciplined URL management to prevent wasted crawl activity.
Conclusion: Building Links Based on Real Crawl Behavior
Log file link analysis changes how link value is understood. Instead of relying on assumed metrics, it shows how search engines actually discover, follow, and use links in real crawl environments.
By working with crawl confirmed data, backlinks can be validated accurately, hidden discovery paths become visible, and lost link equity can be recovered through better internal routing and structural fixes. This results in more efficient link building, better use of budgets, and strategies grounded in real crawler behavior rather than estimates.
As search continues to evolve with AI systems and multiple crawler types, understanding crawl behavior is no longer optional. Teams that rely on verified crawl data make smarter decisions, reduce wasted effort, and build link profiles that remain effective as algorithms change.
If you want link building decisions driven by real crawl insight instead of assumptions,T-RANKS helps brands turn server-level data into scalable, results-driven link growth. Our approach focuses on links that search engines actually follow and use.
FAQs About Log File Link Analysis
What is log file link analysis in SEO?
Log file link analysis is the process of using server logs to see how Googlebot actually discovers and crawls backlinks. It relies on real crawl behavior instead of estimated backlink data from third-party tools.
How is log file link analysis different from backlink analysis tools?
Log file link analysis shows which backlinks Googlebot actually follows, while backlink tools only report which links exist. This makes log files more reliable for validating real SEO impact.
Do backlinks that are not crawled still help SEO in 2026?
No, backlinks that are not crawled provide little to no SEO value in 2026. If Googlebot does not visit a link, it cannot consistently pass authority or relevance.
Can log file analysis confirm whether a backlink is working?
Yes, log file analysis confirms a backlink is working when Googlebot reaches your site through it. This is verified using referrer URLs and crawl activity recorded in server logs.
What are referrer URLs in log file link analysis?
Referrer URLs show the page Googlebot visited immediately before landing on your site. They identify the exact external pages that triggered crawl discovery.
Can log files reveal backlinks that SEO tools miss?
Yes, log files often uncover hidden or unreported backlinks. Any external page that sends Googlebot traffic will appear in logs, even if SEO tools cannot detect it.
What are orphan backlinks, and how do logs help identify them?
Orphan backlinks point to pages that are broken, redirected, or poorly connected internally. Logs reveal them when Googlebot repeatedly hits error pages from external referrers.
Does crawl frequency indicate backlink quality?
Crawl frequency can indicate relative importance, but it is not a standalone quality signal. It must be evaluated alongside relevance, link context, internal routing, and indexability.
How does log file link analysis improve link building strategy?
Log file link analysis helps prioritize backlinks that actually drive crawl activity. This allows link building efforts to focus on sources Googlebot clearly values.
Is log file link analysis useful for small websites?
Log file link analysis becomes useful for small websites once they actively build links or scale content. Without consistent crawl activity, log data may be too limited for meaningful insights.